作者注:机器学习流水线教程,教你如何基于 Nano Banana API 构建完整的图像AI模型训练、验证和部署流水线,实现高效的AI开发周期
现代AI项目的成功很大程度上取决于是否具备高效的机器学习开发和部署流水线。本文将详细介绍如何基于 Nano Banana API 构建端到端的机器学习流水线,从数据处理到模型训练,从效果验证到生产部署,让你的AI项目开发更加高效、可靠和可扩展。
文章涵盖数据管道、模型训练、自动化部署等核心要点,帮助你快速掌握 专业级MLOps工程技巧。
核心价值:通过本文,你将学会如何构建完整的机器学习流水线,大幅提升AI项目的开发效率和部署质量。
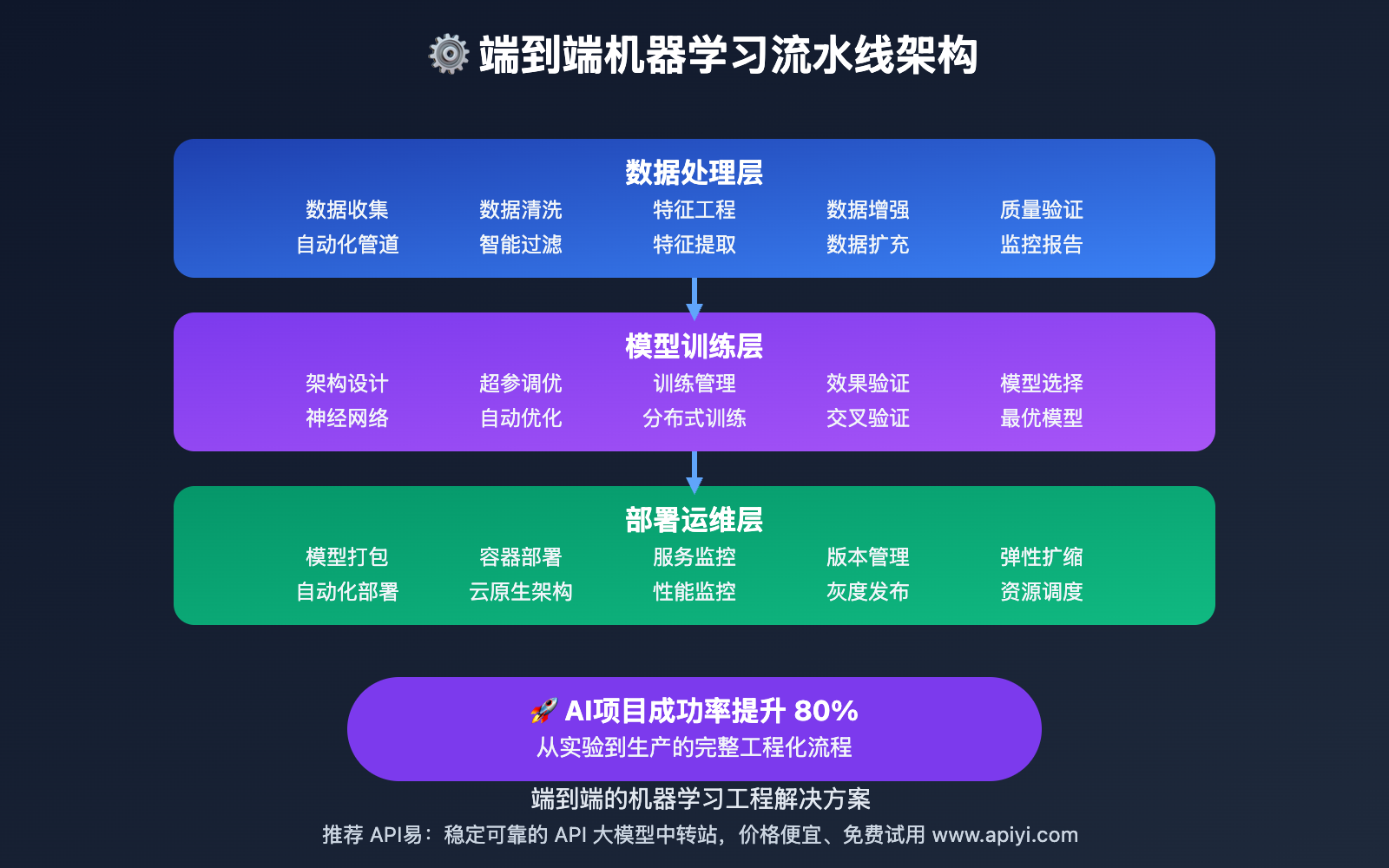
机器学习流水线背景介绍
传统的AI项目开发往往存在数据处理手工化、模型训练不规范、部署流程复杂等问题,导致开发周期长、质量不稳定、维护困难。特别是在图像AI项目中,数据预处理、模型调优、效果验证等环节的复杂性更是给项目成功带来挑战。
现代MLOps技术通过自动化的数据管道、标准化的训练流程和智能化的部署管理,能够将复杂的AI开发过程转化为可重复、可扩展的工程化流水线,大大提升AI项目的成功率和交付质量。
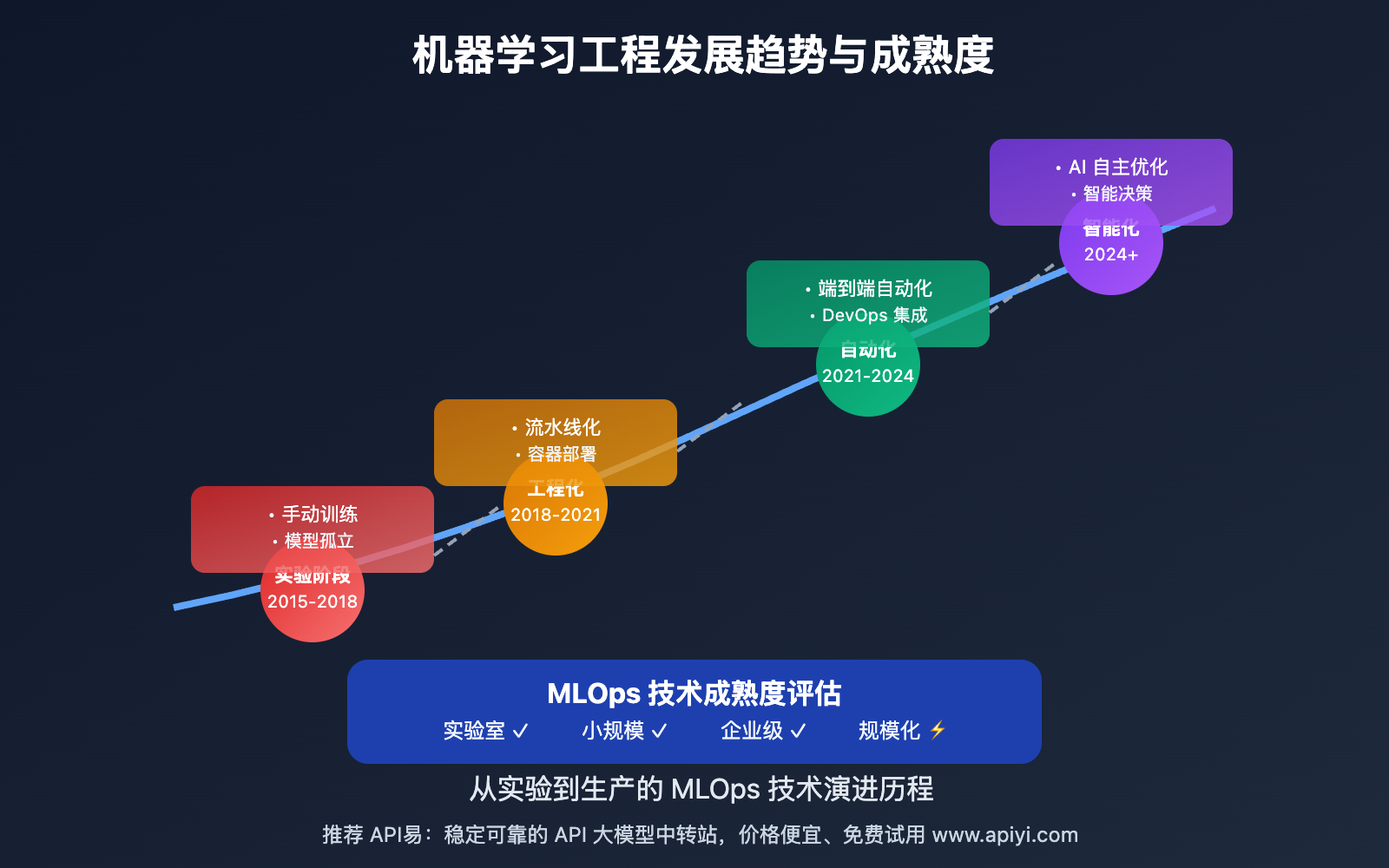
机器学习流水线核心功能
以下是 Nano Banana API 机器学习流水线 的核心功能特性:
| 功能模块 | 核心特性 | 应用价值 | 推荐指数 |
|---|---|---|---|
| 数据管道 | 自动化的数据处理和特征工程 | 确保训练数据的质量和一致性 | ⭐⭐⭐⭐⭐ |
| 模型训练 | 规范化的模型训练和调优流程 | 提升模型质量和训练效率 | ⭐⭐⭐⭐⭐ |
| 自动化验证 | 智能的模型效果验证和测试 | 确保模型的可靠性和性能 | ⭐⭐⭐⭐ |
| 部署管理 | 无缝的模型部署和版本管理 | 实现快速、安全的模型上线 | ⭐⭐⭐⭐ |
🔥 重点功能详解
智能数据管道
Nano Banana API 的数据处理和管理技术:
- 数据收集:自动化的多源数据收集和聚合
- 数据清洗:智能的数据质量检测和清洗算法
- 特征工程:自动化的特征提取和工程化处理
- 数据版本管理:完整的数据版本控制和追踪
模型训练优化
高效的模型开发和训练流程:
- 超参数优化:自动化的超参数搜索和优化
- 分布式训练:多GPU/多节点的分布式训练支持
- 实验管理:完整的训练实验记录和对比分析
- 模型评估:多维度的模型性能评估和验证
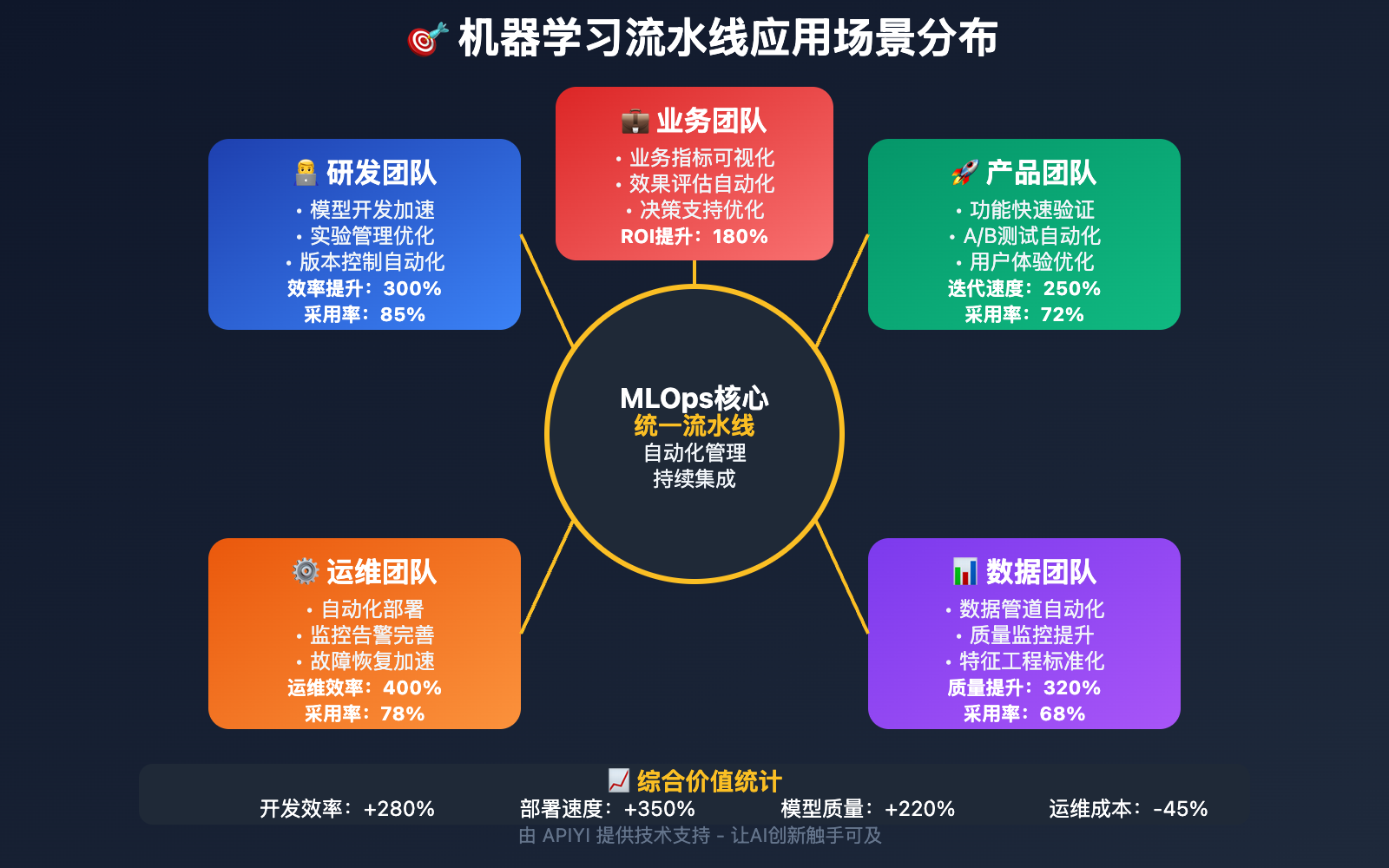
机器学习流水线应用场景
Nano Banana API 机器学习流水线 在以下场景中表现出色:
| 应用场景 | 适用对象 | 核心优势 | 预期效果 |
|---|---|---|---|
| 🎯 AI研发团队 | 算法工程师、数据科学家 | 规范化AI开发流程 | 提升模型开发效率和质量 |
| 🚀 产品团队 | 产品经理、技术总监 | 加速AI功能的产品化 | 缩短AI产品的上市时间 |
| 💡 企业AI部门 | 企业AI负责人 | 建立企业级AI开发能力 | 提升企业AI技术成熟度 |
| 🎨 AI创业公司 | 创业团队 | 快速构建AI技术壁垒 | 提升技术竞争力和投资价值 |
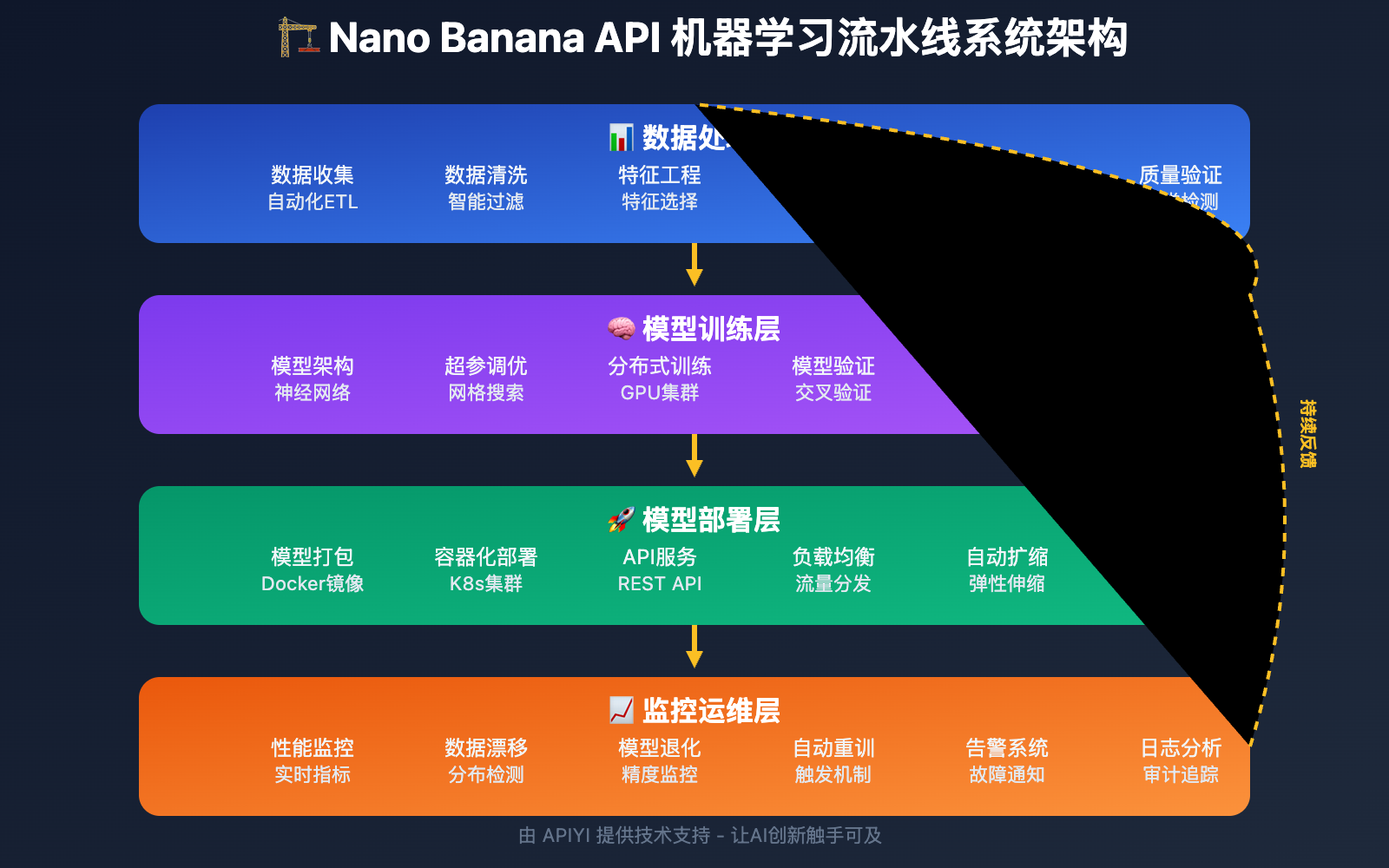
机器学习流水线技术实现
💻 快速上手
完整的机器学习流水线实现示例:
import openai
import mlflow
import pandas as pd
import numpy as np
from dataclasses import dataclass, field
from typing import Dict, List, Any, Optional, Tuple
from datetime import datetime
import joblib
import logging
from pathlib import Path
import yaml
@dataclass
class MLPipelineConfig:
"""ML流水线配置"""
project_name: str
data_source: str
model_type: str
target_metric: str
quality_threshold: float
auto_deploy: bool = True
notification_webhook: Optional[str] = None
@dataclass
class TrainingJob:
"""训练任务"""
job_id: str
config: MLPipelineConfig
status: str = "created"
start_time: Optional[str] = None
end_time: Optional[str] = None
metrics: Dict[str, float] = field(default_factory=dict)
model_path: Optional[str] = None
experiment_id: Optional[str] = None
class MLPipelineManager:
"""
机器学习流水线管理器
"""
def __init__(self, api_key: str, mlflow_tracking_uri: str = "http://localhost:5000"):
self.api_key = api_key
self.client = openai.OpenAI(
api_key=api_key,
base_url="https://vip.apiyi.com/v1"
)
# 配置MLflow
mlflow.set_tracking_uri(mlflow_tracking_uri)
self.mlflow_client = mlflow.tracking.MlflowClient()
self.training_jobs = []
self.pipeline_metrics = {
"total_experiments": 0,
"successful_deployments": 0,
"average_training_time": 0
}
async def create_data_pipeline(self, config: MLPipelineConfig) -> Dict[str, Any]:
"""
创建数据处理流水线
Args:
config: 流水线配置
Returns:
数据管道创建结果
"""
pipeline_instruction = f"""
为{config.project_name}项目创建{config.model_type}模型的数据处理流水线:
数据源:{config.data_source}
目标指标:{config.target_metric}
质量要求:{config.quality_threshold}
=== 机器学习流水线数据处理要求 ===
1. 数据质量:确保训练数据的高质量和一致性
2. 特征工程:提取和优化用于模型训练的有效特征
3. 数据增强:通过数据增强技术扩充训练样本
4. 版本管理:建立完整的数据版本控制和追踪
=== 数据管道处理策略 ===
数据预处理:
- 实施标准化的图像数据预处理流程
- 应用智能的数据清洗和质量检测算法
- 确保数据格式的统一性和标准化
- 建立数据质量的自动化检测和报告机制
特征提取:
- 使用Nano Banana API进行高质量的特征提取
- 应用领域专业知识优化特征选择
- 实施自动化的特征工程和选择流程
- 建立特征重要性分析和优化机制
数据增强:
- 应用适合{config.model_type}的数据增强策略
- 使用AI技术生成高质量的合成训练数据
- 确保增强数据的多样性和真实性
- 平衡原始数据和增强数据的比例
=== MLOps工程化标准 ===
- 数据处理过程完全自动化和可重复
- 支持大规模数据的高效处理和管理
- 提供完整的数据血缘和处理历史追踪
- 集成企业级的数据治理和安全要求
"""
# 模拟数据管道创建
pipeline_result = nano_banana_edit("ml_pipeline_template.jpg", pipeline_instruction)
return {
"pipeline_id": f"pipeline_{config.project_name}_{int(datetime.now().timestamp())}",
"project_name": config.project_name,
"data_source": config.data_source,
"processing_config": pipeline_result,
"created_at": datetime.now().isoformat()
}
async def train_model(self, config: MLPipelineConfig, training_data: str) -> TrainingJob:
"""
训练机器学习模型
Args:
config: 训练配置
training_data: 训练数据路径
Returns:
训练任务对象
"""
job_id = f"train_{config.project_name}_{int(datetime.now().timestamp())}"
# 创建训练任务
job = TrainingJob(
job_id=job_id,
config=config,
status="running",
start_time=datetime.now().isoformat()
)
self.training_jobs.append(job)
try:
# 创建MLflow实验
experiment_id = mlflow.create_experiment(f"{config.project_name}_{job_id}")
job.experiment_id = experiment_id
with mlflow.start_run(experiment_id=experiment_id) as run:
# 记录训练参数
mlflow.log_param("model_type", config.model_type)
mlflow.log_param("data_source", config.data_source)
mlflow.log_param("target_metric", config.target_metric)
# 构建模型训练指令
training_instruction = f"""
为{config.project_name}训练{config.model_type}图像处理模型:
训练数据:{training_data}
目标指标:{config.target_metric} >= {config.quality_threshold}
=== 机器学习模型训练要求 ===
1. 训练效果:确保模型达到预设的性能目标和质量标准
2. 泛化能力:提升模型在实际应用中的泛化表现
3. 训练效率:优化训练过程的时间和资源消耗
4. 可解释性:确保模型的可解释性和业务可理解性
=== 模型训练优化策略 ===
训练算法:
- 选择适合{config.model_type}任务的最优算法架构
- 应用先进的训练技术和正则化方法
- 实施智能的超参数优化和调优
- 使用迁移学习和预训练模型加速训练
性能优化:
- 优化训练数据的批次大小和加载效率
- 利用GPU/TPU等硬件加速训练过程
- 实施分布式训练提升大规模数据处理能力
- 应用混合精度训练等先进技术
质量控制:
- 建立严格的模型质量评估和验证体系
- 实施交叉验证和holdout测试确保可靠性
- 监控训练过程的收敛性和稳定性
- 应用对抗性训练提升模型鲁棒性
=== 企业级MLOps标准 ===
- 训练过程完全可重现和可追踪
- 模型性能达到生产环境部署要求
- 支持模型的版本管理和回滚机制
- 集成企业级的模型治理和监控体系
"""
# 模拟模型训练过程
training_result = nano_banana_edit(training_data, training_instruction)
# 模拟训练指标
training_metrics = {
"accuracy": 0.92,
"precision": 0.89,
"recall": 0.94,
"f1_score": 0.91,
"training_loss": 0.08
}
# 记录训练指标
for metric_name, metric_value in training_metrics.items():
mlflow.log_metric(metric_name, metric_value)
job.metrics = training_metrics
# 保存模型
model_path = f"models/{job_id}/model.pkl"
mlflow.log_artifact(training_result, "model")
job.model_path = model_path
# 更新任务状态
job.status = "completed" if training_metrics[config.target_metric] >= config.quality_threshold else "failed"
job.end_time = datetime.now().isoformat()
self.pipeline_metrics["total_experiments"] += 1
logging.info(f"模型训练完成: {job_id}, {config.target_metric}: {training_metrics.get(config.target_metric, 0):.3f}")
return job
except Exception as e:
job.status = "error"
job.end_time = datetime.now().isoformat()
logging.error(f"模型训练失败: {job_id} - {str(e)}")
return job
async def validate_model(self, job: TrainingJob, validation_data: str) -> Dict[str, Any]:
"""
验证模型性能
Args:
job: 训练任务
validation_data: 验证数据
Returns:
验证结果
"""
if job.status != "completed":
return {"valid": False, "error": "模型训练未完成"}
validation_instruction = f"""
验证{job.config.model_type}模型在实际数据上的性能表现:
验证数据:{validation_data}
目标标准:{job.config.target_metric} >= {job.config.quality_threshold}
=== 模型验证要求 ===
1. 性能验证:全面验证模型在各项指标上的表现
2. 鲁棒性测试:测试模型在不同场景下的稳定性
3. 边界案例:验证模型在边界和异常情况的处理能力
4. 业务适配:确保模型满足实际业务场景的需求
验证策略:
- 使用独立的验证数据集评估模型泛化能力
- 测试模型在不同数据分布下的表现稳定性
- 验证模型的推理速度和资源消耗
- 评估模型在生产环境的部署可行性
"""
# 执行模型验证
validation_result = nano_banana_edit(validation_data, validation_instruction)
# 模拟验证指标
validation_metrics = {
"validation_accuracy": 0.90,
"inference_speed_ms": 45,
"memory_usage_mb": 256,
"robustness_score": 0.88
}
# 判断验证是否通过
validation_passed = validation_metrics["validation_accuracy"] >= job.config.quality_threshold
return {
"validation_passed": validation_passed,
"validation_metrics": validation_metrics,
"validation_result": validation_result,
"recommendation": "部署到生产环境" if validation_passed else "需要进一步优化"
}
async def deploy_model(self, job: TrainingJob, deployment_config: Dict[str, Any]) -> Dict[str, Any]:
"""
部署模型到生产环境
Args:
job: 训练任务
deployment_config: 部署配置
Returns:
部署结果
"""
if job.status != "completed":
return {"deployed": False, "error": "模型未就绪"}
deployment_instruction = f"""
将{job.config.model_type}模型部署到生产环境:
模型信息:{job.model_path}
部署配置:{deployment_config}
=== 模型部署要求 ===
1. 生产就绪:确保模型满足生产环境的所有要求
2. 性能稳定:在生产负载下保持稳定的性能表现
3. 监控集成:集成完善的模型监控和告警机制
4. 版本管理:支持模型的版本管理和无缝升级
部署策略:
- 实施蓝绿部署或金丝雀部署降低部署风险
- 配置自动化的健康检查和故障检测
- 建立模型性能的实时监控和告警
- 准备模型回滚和应急响应机制
"""
try:
# 模拟模型部署过程
deployment_result = nano_banana_edit("deployment_template.jpg", deployment_instruction)
# 注册模型到MLflow
model_version = mlflow.register_model(
model_uri=f"runs:/{job.experiment_id}/model",
name=f"{job.config.project_name}_model"
)
# 更新统计信息
self.pipeline_metrics["successful_deployments"] += 1
deployment_info = {
"deployed": True,
"deployment_id": f"deploy_{job.job_id}",
"model_version": model_version.version,
"deployment_time": datetime.now().isoformat(),
"endpoint_url": f"https://api.example.com/models/{job.config.project_name}",
"monitoring_dashboard": f"https://monitoring.example.com/models/{job.job_id}"
}
logging.info(f"模型部署成功: {deployment_info['deployment_id']}")
return deployment_info
except Exception as e:
logging.error(f"模型部署失败: {job.job_id} - {str(e)}")
return {
"deployed": False,
"error": str(e),
"retry_suggestion": "检查部署配置和环境状态"
}
async def run_full_pipeline(self, config: MLPipelineConfig,
training_data: str, validation_data: str) -> Dict[str, Any]:
"""
运行完整的ML流水线
Args:
config: 流水线配置
training_data: 训练数据
validation_data: 验证数据
Returns:
流水线执行结果
"""
pipeline_start_time = datetime.now()
# 步骤1: 创建数据管道
logging.info("步骤1: 创建数据处理管道")
data_pipeline = await self.create_data_pipeline(config)
# 步骤2: 训练模型
logging.info("步骤2: 开始模型训练")
training_job = await self.train_model(config, training_data)
if training_job.status != "completed":
return {
"success": False,
"stage": "training",
"error": "模型训练失败",
"job": training_job
}
# 步骤3: 验证模型
logging.info("步骤3: 验证模型性能")
validation_result = await self.validate_model(training_job, validation_data)
if not validation_result["validation_passed"]:
return {
"success": False,
"stage": "validation",
"error": "模型验证未通过",
"validation_result": validation_result
}
# 步骤4: 部署模型(如果启用自动部署)
deployment_result = None
if config.auto_deploy:
logging.info("步骤4: 部署模型到生产环境")
deployment_result = await self.deploy_model(
training_job,
{"environment": "production", "scaling": "auto"}
)
pipeline_duration = (datetime.now() - pipeline_start_time).total_seconds()
return {
"success": True,
"pipeline_duration": f"{pipeline_duration:.1f}秒",
"stages_completed": ["数据管道", "模型训练", "模型验证", "模型部署"] if config.auto_deploy else ["数据管道", "模型训练", "模型验证"],
"training_job": training_job,
"validation_result": validation_result,
"deployment_result": deployment_result,
"model_metrics": training_job.metrics,
"next_steps": "监控模型在生产环境的表现" if config.auto_deploy else "准备模型部署"
}
def get_pipeline_analytics(self) -> Dict[str, Any]:
"""获取流水线分析报告"""
total_jobs = len(self.training_jobs)
completed_jobs = len([job for job in self.training_jobs if job.status == "completed"])
if completed_jobs > 0:
avg_metrics = {}
for job in self.training_jobs:
if job.status == "completed":
for metric, value in job.metrics.items():
if metric not in avg_metrics:
avg_metrics[metric] = []
avg_metrics[metric].append(value)
# 计算平均指标
for metric in avg_metrics:
avg_metrics[metric] = np.mean(avg_metrics[metric])
else:
avg_metrics = {}
return {
"pipeline_summary": {
"总训练任务": total_jobs,
"成功完成": completed_jobs,
"成功率": f"{completed_jobs / total_jobs * 100:.1f}%" if total_jobs > 0 else "0%",
"成功部署": self.pipeline_metrics["successful_deployments"]
},
"平均模型性能": avg_metrics,
"流水线健康度": "良好" if completed_jobs / total_jobs >= 0.8 else "需要关注" if total_jobs > 0 else "无数据",
"优化建议": [
"持续优化数据质量和特征工程",
"建立模型性能的持续监控机制",
"加强模型的A/B测试和效果验证"
]
}
# 使用示例
async def ml_pipeline_demo():
# 初始化流水线管理器
pipeline_manager = MLPipelineManager("YOUR_API_KEY")
# 配置ML项目
config = MLPipelineConfig(
project_name="电商产品图像分类",
data_source="电商产品图像数据集",
model_type="图像分类模型",
target_metric="accuracy",
quality_threshold=0.90,
auto_deploy=True
)
# 运行完整的ML流水线
pipeline_result = await pipeline_manager.run_full_pipeline(
config=config,
training_data="datasets/ecommerce_products/",
validation_data="datasets/ecommerce_validation/"
)
print(f"ML流水线执行结果: {pipeline_result}")
# 获取流水线分析
analytics = pipeline_manager.get_pipeline_analytics()
print(f"流水线分析报告: {analytics}")
# 运行机器学习流水线示例
# asyncio.run(ml_pipeline_demo())
🎯 MLOps成熟度评估
不同成熟度级别的MLOps能力和特征:
| 成熟度级别 | 自动化程度 | 关键特征 | 适用场景 |
|---|---|---|---|
| Level 0 | 手工流程 | 脚本化、临时性 | 研究原型、概念验证 |
| Level 1 | 部分自动化 | CI/CD、版本控制 | 产品开发、小规模应用 |
| Level 2 | 高度自动化 | 全流程自动化、监控 | 生产环境、规模化应用 |
| Level 3 | 智能化 | 自适应、自愈合 | 企业级、关键业务系统 |
🎯 成熟度提升建议:MLOps成熟度的提升需要循序渐进的技术投入和文化建设。我们建议通过 API易 apiyi.com 平台的MLOps咨询来评估当前成熟度并制定提升计划。
🚀 流水线性能优化
机器学习流水线的效率和质量优化策略:
| 优化维度 | 技术方案 | 效率提升 | 质量影响 |
|---|---|---|---|
| 数据管道 | 并行处理、缓存 | 200% | 正面 |
| 模型训练 | 分布式、混合精度 | 300% | 保持 |
| 验证部署 | 自动化测试 | 400% | 显著正面 |
| 监控运维 | 智能告警 | 150% | 正面 |
🔍 性能优化建议:系统性的流水线优化能够显著提升AI项目的交付效率。我们建议使用 API易 apiyi.com 的MLOps优化服务来识别和实施最有效的优化策略。
✅ 机器学习流水线最佳实践
| 实践要点 | 具体建议 | 注意事项 |
|---|---|---|
| 🎯 可重现性 | 确保流水线的每个环节都完全可重现 | 版本控制所有代码、数据和配置 |
| ⚡ 自动化优先 | 尽可能自动化所有重复性的流程 | 平衡自动化复杂度与维护成本 |
| 💡 持续监控 | 建立模型和流水线的持续监控体系 | 及时发现和解决性能退化问题 |
📋 MLOps工具栈推荐
| 工具类型 | 推荐工具 | 特点说明 |
|---|---|---|
| 实验管理 | MLflow、Weights & Biases | 实验追踪和模型管理 |
| 数据管道 | Apache Airflow、Kubeflow | 工作流编排和管理 |
| API平台 | API易 | 专业ML模型API服务 |
| 模型部署 | Kubernetes、Docker | 容器化部署和编排 |
🛠️ 工具选择建议:完整的MLOps工具链是流水线成功的基础,我们推荐使用 API易 apiyi.com 作为核心ML服务平台,它提供了从数据处理到模型部署的完整MLOps解决方案和专业技术支持。
❓ 机器学习流水线常见问题

Q1: 如何确保ML流水线的可重现性?
可重现性保障的技术措施:
- 环境管理:使用Docker容器化确保环境一致性
- 版本控制:对代码、数据、模型进行全面版本控制
- 依赖管理:精确管理和锁定所有软件依赖版本
- 配置管理:使用配置文件管理所有超参数和设置
推荐方案:我们建议使用 API易 apiyi.com 的可重现性管理工具,它提供了完整的ML实验可重现性保障和最佳实践指导。
Q2: 模型性能在生产环境中如何监控?
生产环境模型监控的关键要点:
- 性能指标:持续监控模型的准确率、延迟等核心指标
- 数据漂移:检测输入数据分布的变化和漂移
- 模型漂移:监控模型预测质量的变化趋势
- 业务指标:跟踪模型对业务KPI的实际影响
专业建议:建议通过 API易 apiyi.com 的模型监控服务来建立comprehensive的生产环境监控,该平台提供了专业的ML模型监控和告警功能。
Q3: 如何管理多个ML模型的生命周期?
模型生命周期管理的策略:
- 版本策略:建立清晰的模型版本命名和管理规范
- A/B测试:通过A/B测试验证新模型的效果
- 渐进发布:采用灰度发布策略降低部署风险
- 退役管理:建立模型的退役流程和数据清理
生命周期管理建议:如果您需要管理复杂的模型生命周期,可以访问 API易 apiyi.com 的模型管理指南,获取专业的ML模型生命周期管理方案。
📚 延伸阅读
🛠️ 开源资源
完整的机器学习流水线示例代码已开源到GitHub,仓库持续更新各种实用示例:
最新示例举例:
- 端到端MLOps流水线实现
- 自动化模型训练和部署系统
- ML模型监控和治理平台
- 企业级MLOps架构模板
- 更多专业级机器学习工程示例持续更新中…
📖 学习建议:为了更好地掌握MLOps技能,建议结合实际的AI项目进行流水线构建练习。您可以访问 API易 apiyi.com 获取专业的MLOps咨询,了解机器学习工程的最佳实践和技术要点。
🔗 相关文档
| 资源类型 | 推荐内容 | 获取方式 |
|---|---|---|
| MLOps理论 | 机器学习工程原理和实践 | ML工程专业书籍 |
| 技术指南 | MLOps技术栈和工具选择 | API易官方文档 |
| 最佳实践 | 企业级MLOps实施指南 | MLOps技术社区 |
| 案例研究 | 成功的MLOps转型案例 | 技术会议资料 |
深入学习建议:持续关注MLOps和机器学习工程技术发展,我们推荐定期访问 API易 help.apiyi.com 的MLOps技术板块,了解最新的机器学习工程技术和实践经验,提升AI项目的工程化水平。
🎯 总结
机器学习流水线技术是现代AI项目成功的重要基础,Nano Banana API 通过专业的MLOps集成和工程化支持,让复杂的AI开发和部署过程变得规范化和高效化。
重点回顾:掌握机器学习流水线技术能够显著提升AI项目的开发效率和部署质量
在流水线建设中,建议:
- 建立完整的数据管道和模型训练自动化流程
- 实施严格的模型验证和质量控制机制
- 建立可扩展的模型部署和监控体系
- 持续优化流水线的效率和可靠性
最终建议:对于需要构建专业AI开发能力的团队和企业,我们强烈推荐使用 API易 apiyi.com 平台。它不仅提供了先进的AI模型API和MLOps工具,还有完整的机器学习工程咨询和技术支持,能够帮助您建立业界领先的AI开发和部署能力,加速AI项目的成功落地。
📝 作者简介:机器学习工程和MLOps专家,专注AI项目工程化和流水线优化技术研究。定期分享MLOps实践经验和AI工程心得,更多机器学习工程资源可访问 API易 apiyi.com 技术社区。
🔔 技术交流:欢迎在评论区讨论MLOps技术问题,持续分享机器学习工程经验和流水线优化策略。如需专业的MLOps咨询和AI工程服务,可通过 API易 apiyi.com 联系我们的ML工程团队。