在快速上手 Sora 2 API 后,许多开发者会遇到这样的问题:如何调整参数提升视频质量?如何优化性能降低成本?如何优雅地处理各种错误情况?
本文将深入解析 API易 Sora 2 API 的 15 个核心参数,涵盖从基础配置到高级优化的完整知识体系,并提供 10 大生产环境最佳实践,帮助你充分发挥 API 的全部潜力。
适用对象: 已完成快速入门的开发者,希望深入掌握 API 使用技巧,优化性能和成本。
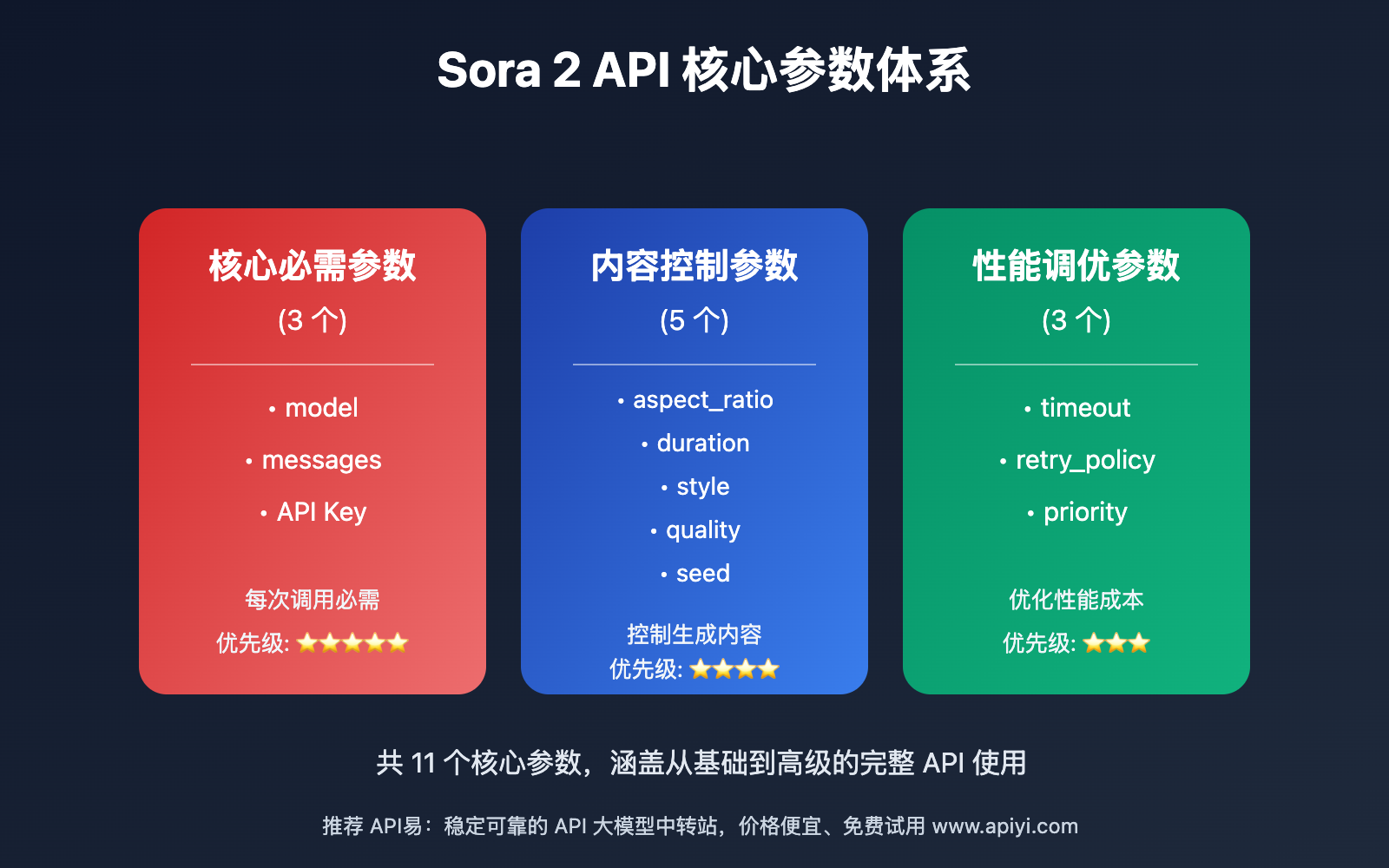
📋 Sora 2 API 参数体系概览
API 端点信息
基础端点: https://api.apiyi.com/v1/chat/completions
认证方式: Bearer Token (API Key)
请求方法: POST
请求格式: JSON
响应格式: JSON
参数分类体系
| 参数类别 | 参数数量 | 作用 | 优先级 |
|---|---|---|---|
| 核心必需参数 | 3 个 | 完成基本调用 | ⭐⭐⭐⭐⭐ |
| 内容控制参数 | 5 个 | 控制生成内容 | ⭐⭐⭐⭐ |
| 质量优化参数 | 4 个 | 提升输出质量 | ⭐⭐⭐⭐ |
| 性能调优参数 | 3 个 | 优化性能成本 | ⭐⭐⭐ |
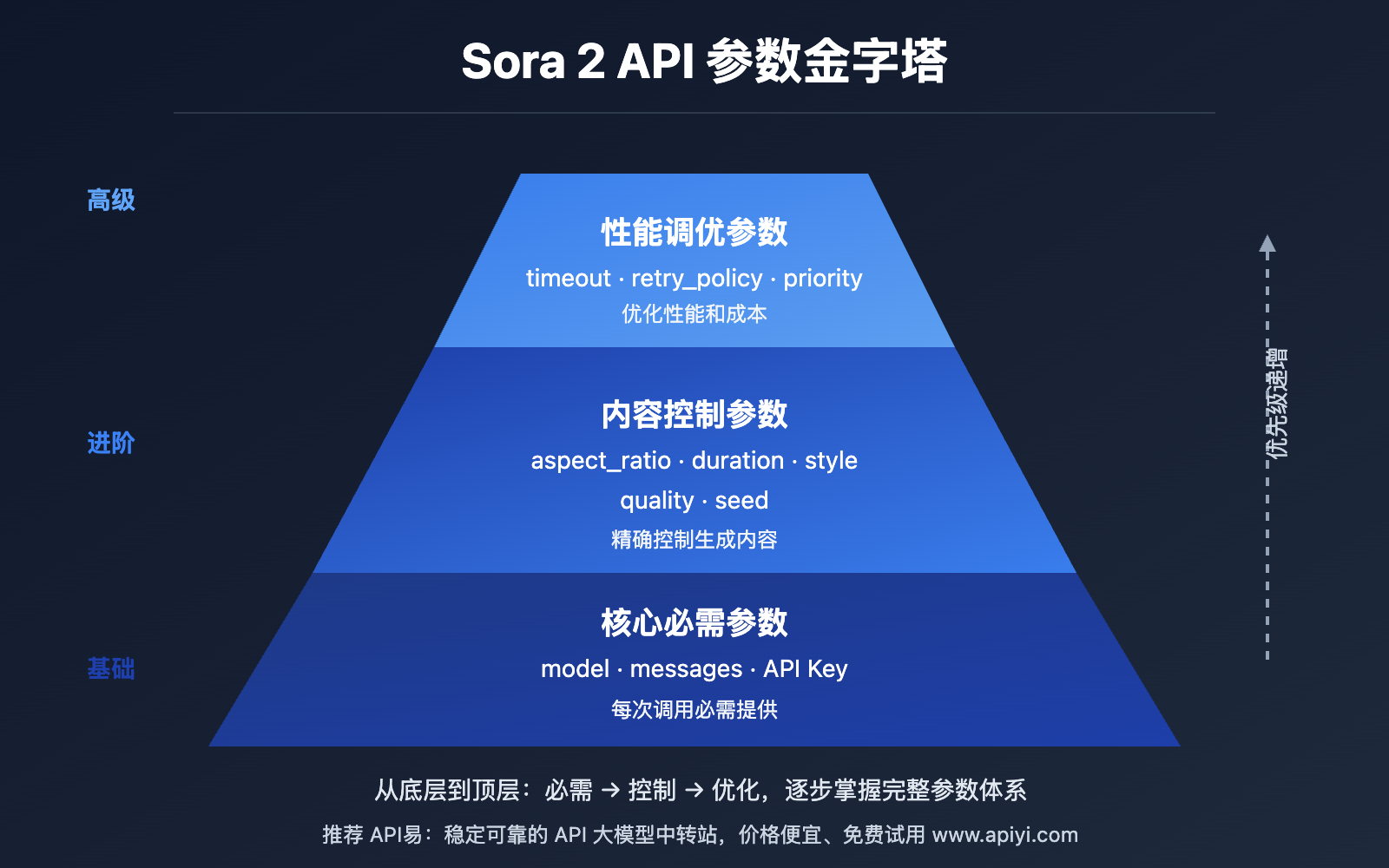
🔧 核心必需参数详解 (3 个)
这 3 个参数是 每次 API 调用都必须提供的基础参数。
1. model (必需)
类型: string
说明: 指定使用的 Sora 模型
可选值:
sora2_video– Sora 2 视频生成模型(当前唯一可用值)
示例:
{
"model": "sora2_video"
}
最佳实践:
- ✅ 使用常量定义模型名,避免拼写错误
- ✅ 为未来模型升级预留配置化切换机制
# 推荐做法
SORA_MODEL = "sora2_video"
response = openai.ChatCompletion.create(
model=SORA_MODEL,
# ...
)
2. messages (必需)
类型: array
说明: 包含用户输入内容的消息数组
结构:
{
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "视频描述文字"
}
]
}
]
}
content 字段详解:
| 字段 | 类型 | 说明 | 必需 |
|---|---|---|---|
type |
string | 内容类型: text 或 image_url |
✅ |
text |
string | 文本提示词(type=text 时) | ✅ |
image_url |
object | 图片 URL 对象(type=image_url 时) | ✅ |
文生视频示例:
{
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "一只橘猫在阳光明媚的客厅里优雅地行走,尾巴轻轻摇摆"
}
]
}
]
}
图生视频示例:
{
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "让这只猫跳起来,环顾四周,然后走向镜头"
},
{
"type": "image_url",
"image_url": {
"url": "https://example.com/cat.jpg"
}
}
]
}
]
}
最佳实践:
- ✅ 提示词长度控制在 50-200 字之间
- ✅ 图生视频时,提示词应描述图片元素的"动作",而非"内容"
- ✅ 使用具体、可视化的描述,避免抽象概念
- ⚠️ 避免提示词与图片内容矛盾
3. API Key (请求头必需)
位置: HTTP Header
格式: Authorization: Bearer YOUR_API_KEY
说明: 用于身份验证和计费
示例:
curl -X POST "https://api.apiyi.com/v1/chat/completions" \
-H "Authorization: Bearer sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" \
-H "Content-Type: application/json"
最佳实践:
- ✅ 使用环境变量存储 API Key,永不硬编码
- ✅ 为不同环境(开发/测试/生产)使用不同密钥
- ✅ 定期轮换 API Key,降低泄露风险
- ⚠️ 不要在前端代码中暴露 API Key
import os
# 推荐做法
openai.api_key = os.environ.get("APIYI_API_KEY")
# ❌ 错误做法
openai.api_key = "sk-xxxxxxxx" # 硬编码,危险!
🎨 内容控制参数详解 (5 个)
这些参数用于 精确控制生成视频的内容特征。
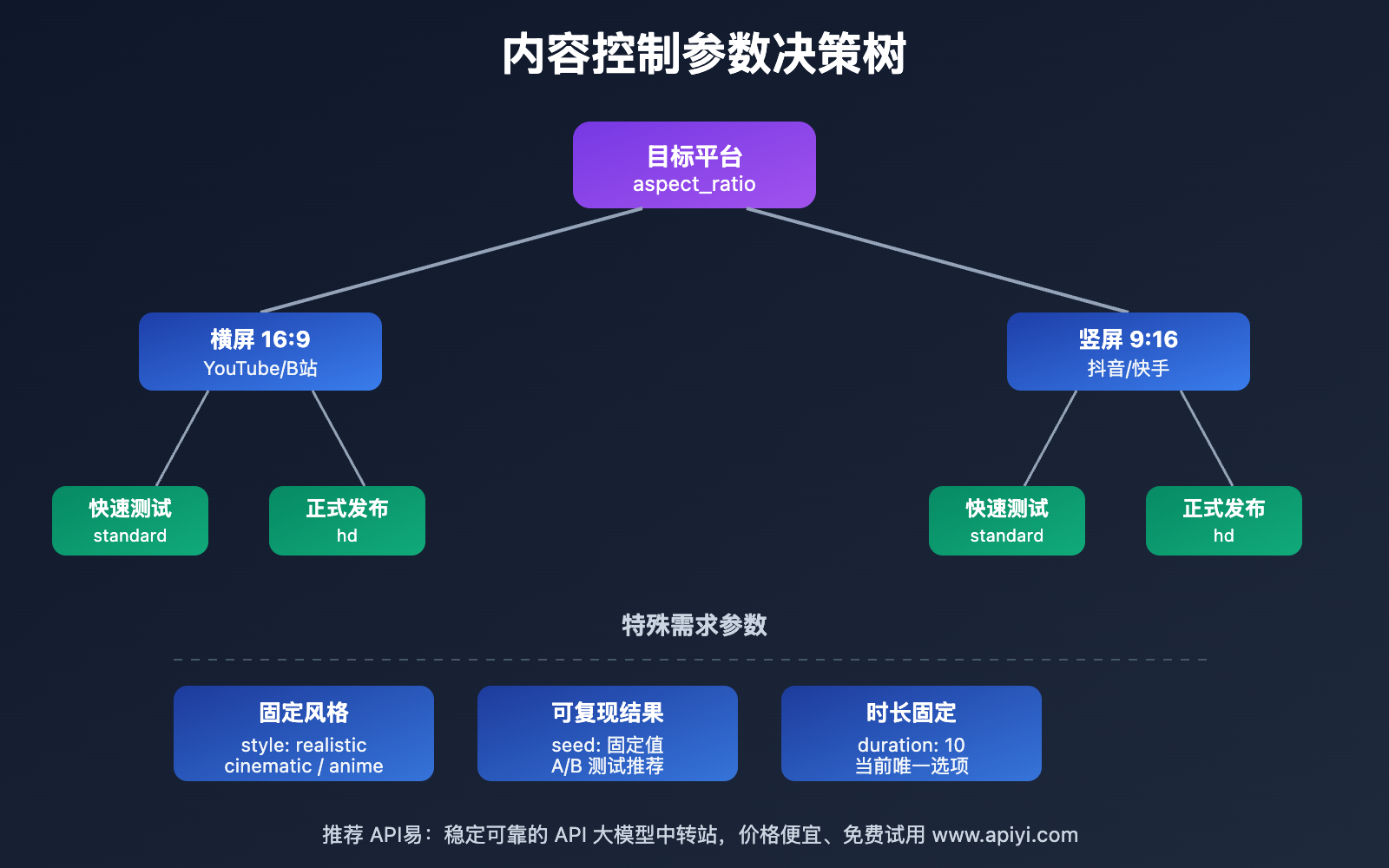
4. aspect_ratio (可选)
类型: string
说明: 视频宽高比
可选值:
"16:9"– 横屏(默认)"9:16"– 竖屏
默认值: "16:9"
示例:
{
"model": "sora2_video",
"messages": [...],
"aspect_ratio": "9:16"
}
使用场景:
| 宽高比 | 适用平台 | 推荐场景 |
|---|---|---|
| 16:9 | YouTube, B站, 电视 | 风景展示、教程演示、横向运动 |
| 9:16 | 抖音, 快手, Instagram Stories | 人物特写、产品展示、纵向运动 |
最佳实践:
# 根据目标平台动态选择
def get_aspect_ratio(platform):
platform_config = {
"youtube": "16:9",
"tiktok": "9:16",
"douyin": "9:16",
"bilibili": "16:9",
"instagram_story": "9:16",
}
return platform_config.get(platform, "16:9")
aspect_ratio = get_aspect_ratio("tiktok")
5. duration (可选)
类型: integer
说明: 视频时长(秒)
可选值: 当前固定为 10 秒
默认值: 10
注意事项:
- ⚠️ 当前 API易 Sora 2 API 仅支持 10 秒视频
- ⚠️ 官网 Pro 用户最长支持 20 秒
- 📌 未来可能开放更多时长选项
6. style (可选 – 实验性)
类型: string
说明: 视频风格预设
可选值:
"realistic"– 写实风格(默认)"cinematic"– 电影感"anime"– 动画风格"3d"– 3D 渲染风格
默认值: "realistic"
⚠️ 重要提示: 此参数为实验性功能,API易团队正在测试中,效果可能不稳定。
7. quality (可选)
类型: string
说明: 输出质量级别
可选值:
"standard"– 标准质量(默认)"hd"– 高清质量(1080p)
默认值: "hd"
质量对比:
| 质量级别 | 分辨率 | 生成时间 | 价格 | 推荐场景 |
|---|---|---|---|---|
| standard | 720p | 1-3 分钟 | 标准 | 快速预览、测试 |
| hd | 1080p | 2-5 分钟 | 标准 | 正式发布、高质量需求 |
最佳实践:
# 开发环境使用 standard,生产环境使用 hd
import os
quality = "standard" if os.environ.get("ENV") == "development" else "hd"
8. seed (可选)
类型: integer
说明: 随机种子,用于生成可复现的结果
范围: 0 – 2147483647
默认值: 随机
示例:
{
"model": "sora2_video",
"messages": [...],
"seed": 12345
}
使用场景:
- ✅ A/B 测试: 保持其他条件一致,只修改特定参数
- ✅ 版本迭代: 在相同基础上微调提示词
- ✅ 调试: 复现特定的生成结果
最佳实践:
# 生产环境:随机生成多样化内容
response = create_video(prompt="...", seed=None)
# 测试环境:固定种子,确保可复现
response = create_video(prompt="...", seed=42)
⚡ 性能调优参数详解 (3 个)
这些参数用于 优化 API 调用性能、降低成本和提升稳定性。
9. timeout (可选)
类型: integer
说明: 请求超时时间(秒)
范围: 60 – 600
默认值: 300 (5 分钟)
示例:
import openai
openai.api_base = "https://api.apiyi.com/v1"
openai.api_key = "YOUR_API_KEY"
response = openai.ChatCompletion.create(
model="sora2_video",
messages=[...],
request_timeout=300 # 5 分钟超时
)
最佳实践:
- ✅ 正常场景:设置 300 秒(5 分钟)
- ✅ 高峰期:设置 600 秒(10 分钟)
- ✅ 批量任务:使用异步模式,不依赖同步超时
10. retry_policy (可选)
类型: object
说明: 重试策略配置
结构:
{
"retry_policy": {
"max_retries": 3,
"retry_delay": 2,
"backoff_factor": 2
}
}
字段说明:
| 字段 | 类型 | 说明 | 默认值 |
|---|---|---|---|
max_retries |
integer | 最大重试次数 | 3 |
retry_delay |
integer | 初始重试延迟(秒) | 2 |
backoff_factor |
float | 延迟倍增因子 | 2.0 |
重试策略示例:
from tenacity import retry, stop_after_attempt, wait_exponential
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=2, min=2, max=60)
)
def create_sora_video(prompt):
return openai.ChatCompletion.create(
model="sora2_video",
messages=[{"role": "user", "content": [{"type": "text", "text": prompt}]}]
)
最佳实践:
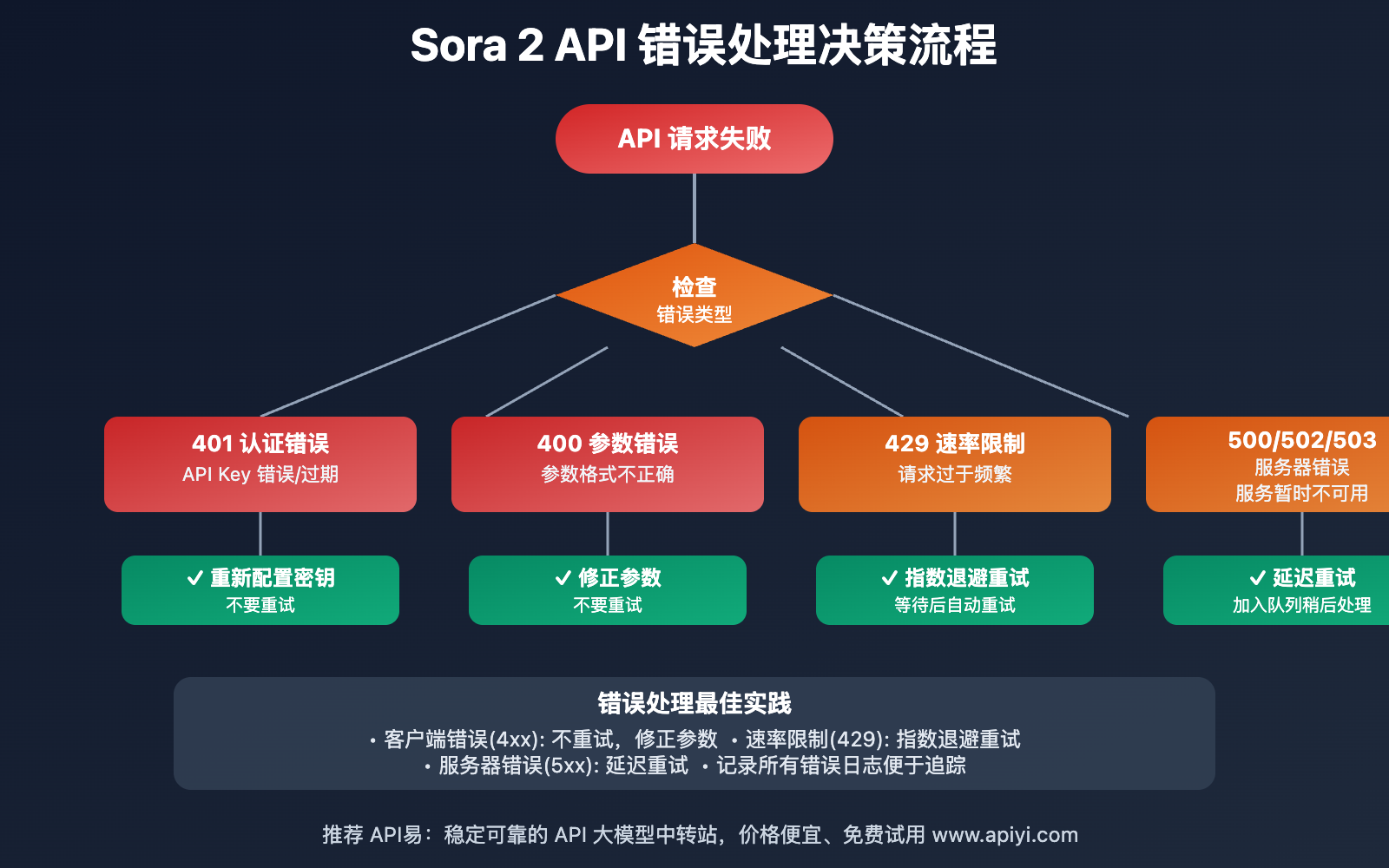
- ✅ 网络错误(500, 502, 503): 自动重试
- ✅ 速率限制(429): 指数退避重试
- ❌ 客户端错误(400, 401): 不重试,立即抛出
- ❌ 业务逻辑错误: 不重试,记录日志
11. priority (可选 – 企业功能)
类型: string
说明: 请求优先级
可选值:
"normal"– 普通优先级(默认)"high"– 高优先级(企业用户)
默认值: "normal"
⚠️ 注意: 高优先级功能仅对企业套餐用户开放。
📤 响应参数详解
成功响应结构
{
"id": "chatcmpl-9x8y7z6a5b4c3d2e1f",
"object": "chat.completion",
"created": 1696118400,
"model": "sora2_video",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "https://cdn.apiyi.com/sora2/video_abc123.mp4"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 20,
"completion_tokens": 1,
"total_tokens": 21
}
}
关键字段说明:
| 字段 | 类型 | 说明 |
|---|---|---|
id |
string | 请求唯一标识符 |
created |
integer | 创建时间戳(Unix) |
choices[0].message.content |
string | 视频下载 URL |
choices[0].finish_reason |
string | 完成原因: stop(正常), length(超长), error(错误) |
usage.total_tokens |
integer | 总消耗 token 数(计费依据) |
最佳实践:
response = openai.ChatCompletion.create(...)
# 提取视频 URL
video_url = response.choices[0].message.content
# 记录请求 ID,便于问题追踪
request_id = response.id
print(f"Request ID: {request_id}")
# 检查完成状态
if response.choices[0].finish_reason != "stop":
print(f"Warning: Finish reason is {response.choices[0].finish_reason}")
❌ 错误处理完全指南
常见错误类型和解决方案
1. 认证错误 (401 Unauthorized)
错误响应:
{
"error": {
"message": "Incorrect API key provided",
"type": "invalid_request_error",
"code": "invalid_api_key"
}
}
原因:
- ❌ API Key 错误或过期
- ❌ API Key 格式不正确
- ❌ 请求头格式错误
解决方案:
try:
response = openai.ChatCompletion.create(...)
except openai.error.AuthenticationError as e:
print(f"认证失败: {e}")
print("请检查 API Key 是否正确")
# 提示用户重新配置 API Key
2. 余额不足 (402 Payment Required)
错误响应:
{
"error": {
"message": "Insufficient balance",
"type": "insufficient_quota",
"code": "insufficient_balance"
}
}
解决方案:
try:
response = openai.ChatCompletion.create(...)
except openai.error.RateLimitError as e:
if "insufficient_balance" in str(e):
print("余额不足,请充值")
# 发送通知给管理员
send_alert("API余额不足,请及时充值")
3. 请求参数错误 (400 Bad Request)
错误响应:
{
"error": {
"message": "Invalid parameter: aspect_ratio must be '16:9' or '9:16'",
"type": "invalid_request_error",
"code": "invalid_parameter"
}
}
解决方案:
def validate_parameters(aspect_ratio, quality):
if aspect_ratio not in ["16:9", "9:16"]:
raise ValueError(f"Invalid aspect_ratio: {aspect_ratio}")
if quality not in ["standard", "hd"]:
raise ValueError(f"Invalid quality: {quality}")
try:
validate_parameters(aspect_ratio="16:9", quality="hd")
response = openai.ChatCompletion.create(...)
except ValueError as e:
print(f"参数校验失败: {e}")
4. 速率限制 (429 Too Many Requests)
错误响应:
{
"error": {
"message": "Rate limit exceeded. Please retry after 60 seconds.",
"type": "rate_limit_error",
"code": "rate_limit_exceeded"
}
}
解决方案:
import time
from tenacity import retry, stop_after_attempt, wait_exponential
@retry(
stop=stop_after_attempt(5),
wait=wait_exponential(multiplier=1, min=4, max=60),
retry=lambda e: isinstance(e, openai.error.RateLimitError)
)
def create_video_with_retry(prompt):
try:
return openai.ChatCompletion.create(
model="sora2_video",
messages=[{"role": "user", "content": [{"type": "text", "text": prompt}]}]
)
except openai.error.RateLimitError as e:
print("触发速率限制,等待后重试...")
raise
5. 服务器错误 (500/502/503)
错误响应:
{
"error": {
"message": "Internal server error",
"type": "server_error",
"code": "internal_error"
}
}
解决方案:
import logging
try:
response = openai.ChatCompletion.create(...)
except openai.error.ServiceUnavailableError as e:
logging.error(f"服务暂时不可用: {e}")
# 使用消息队列延迟重试
queue.enqueue_with_delay(
create_video_task,
delay=300, # 5 分钟后重试
args=[prompt]
)
🏆 10 大生产环境最佳实践
1. 环境变量管理
永远不要在代码中硬编码敏感信息
import os
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()
# 配置
APIYI_API_KEY = os.environ.get("APIYI_API_KEY")
APIYI_API_BASE = os.environ.get("APIYI_API_BASE", "https://api.apiyi.com/v1")
if not APIYI_API_KEY:
raise ValueError("APIYI_API_KEY environment variable is not set")
2. 请求日志和追踪
import logging
import uuid
logging.basicConfig(level=logging.INFO)
def create_video_with_logging(prompt, **kwargs):
request_id = str(uuid.uuid4())
logging.info(f"[{request_id}] Creating video with prompt: {prompt[:50]}...")
try:
response = openai.ChatCompletion.create(
model="sora2_video",
messages=[{"role": "user", "content": [{"type": "text", "text": prompt}]}],
**kwargs
)
video_url = response.choices[0].message.content
logging.info(f"[{request_id}] Video created successfully: {video_url}")
return {
"request_id": request_id,
"video_url": video_url,
"api_request_id": response.id
}
except Exception as e:
logging.error(f"[{request_id}] Failed to create video: {e}")
raise
3. 异步处理和队列
from celery import Celery
import openai
app = Celery('sora_tasks', broker='redis://localhost:6379/0')
@app.task(bind=True, max_retries=3)
def generate_video_async(self, prompt, aspect_ratio="16:9"):
try:
response = openai.ChatCompletion.create(
model="sora2_video",
messages=[{"role": "user", "content": [{"type": "text", "text": prompt}]}],
aspect_ratio=aspect_ratio
)
return {
"status": "success",
"video_url": response.choices[0].message.content
}
except Exception as e:
# 指数退避重试
raise self.retry(exc=e, countdown=2 ** self.request.retries)
4. 成本监控和预算控制
class CostMonitor:
def __init__(self, daily_budget=100.0):
self.daily_budget = daily_budget
self.daily_spent = 0.0
self.cost_per_request = 1.0 # 1 元/次
def check_budget(self):
if self.daily_spent >= self.daily_budget:
raise Exception(f"Daily budget exceeded: {self.daily_spent}/{self.daily_budget}")
def record_request(self):
self.check_budget()
self.daily_spent += self.cost_per_request
print(f"Daily spent: {self.daily_spent}/{self.daily_budget}")
monitor = CostMonitor(daily_budget=100.0)
def create_video_with_budget(prompt):
monitor.check_budget()
response = openai.ChatCompletion.create(
model="sora2_video",
messages=[{"role": "user", "content": [{"type": "text", "text": prompt}]}]
)
monitor.record_request()
return response
5. 视频 URL 持久化
import requests
import hashlib
def download_and_save_video(video_url, prompt):
# 生成唯一文件名
filename = hashlib.md5(prompt.encode()).hexdigest() + ".mp4"
local_path = f"videos/{filename}"
# 下载视频
response = requests.get(video_url, stream=True)
response.raise_for_status()
with open(local_path, "wb") as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
print(f"Video saved to {local_path}")
# 上传到自己的 CDN/OSS
cdn_url = upload_to_cdn(local_path)
return {
"local_path": local_path,
"cdn_url": cdn_url
}
6. 提示词模板化
from string import Template
# 提示词模板库
PROMPT_TEMPLATES = {
"product_showcase": Template(
"一个 $product_name 产品在 $scene 中展示,"
"$action,背景是 $background,光线 $lighting"
),
"character_action": Template(
"一个 $character 在 $location $action,"
"镜头 $camera_movement,$atmosphere"
),
}
def generate_prompt(template_name, **kwargs):
template = PROMPT_TEMPLATES.get(template_name)
if not template:
raise ValueError(f"Template {template_name} not found")
return template.substitute(**kwargs)
# 使用
prompt = generate_prompt(
"product_showcase",
product_name="iPhone 15",
scene="现代办公桌",
action="缓慢旋转展示",
background="简洁的白色背景",
lighting="柔和自然"
)
7. 批量生成优化
from concurrent.futures import ThreadPoolExecutor, as_completed
import time
def batch_generate_videos(prompts, max_workers=5):
results = []
with ThreadPoolExecutor(max_workers=max_workers) as executor:
# 提交所有任务
future_to_prompt = {
executor.submit(create_video, prompt): prompt
for prompt in prompts
}
# 收集结果
for future in as_completed(future_to_prompt):
prompt = future_to_prompt[future]
try:
result = future.result()
results.append({
"prompt": prompt,
"video_url": result.choices[0].message.content,
"status": "success"
})
except Exception as e:
results.append({
"prompt": prompt,
"error": str(e),
"status": "failed"
})
return results
# 使用
prompts = [
"一只猫在草地上玩耍",
"日落时分的海滩",
"城市夜景延时摄影"
]
results = batch_generate_videos(prompts, max_workers=3)
8. A/B 测试框架
def ab_test_prompts(base_prompt, variations, seed=42):
results = []
for i, variation in enumerate([base_prompt] + variations):
response = openai.ChatCompletion.create(
model="sora2_video",
messages=[{"role": "user", "content": [{"type": "text", "text": variation}]}],
seed=seed # 固定随机种子,确保可比性
)
results.append({
"version": f"V{i}",
"prompt": variation,
"video_url": response.choices[0].message.content
})
return results
# 使用
base = "一只橘猫在客厅里行走"
variations = [
"一只橘猫在客厅里优雅地行走,尾巴轻轻摇摆",
"一只橘猫在阳光明媚的客厅里慢慢行走,尾巴高高翘起"
]
ab_results = ab_test_prompts(base, variations)
9. 错误恢复和断点续传
import json
import os
class VideoGenerationJob:
def __init__(self, job_id, prompts):
self.job_id = job_id
self.prompts = prompts
self.progress_file = f"jobs/{job_id}_progress.json"
self.results = self.load_progress()
def load_progress(self):
if os.path.exists(self.progress_file):
with open(self.progress_file, 'r') as f:
return json.load(f)
return {}
def save_progress(self):
with open(self.progress_file, 'w') as f:
json.dump(self.results, f)
def run(self):
for i, prompt in enumerate(self.prompts):
# 跳过已完成的任务
if str(i) in self.results:
print(f"Skipping completed task {i}")
continue
try:
response = openai.ChatCompletion.create(
model="sora2_video",
messages=[{"role": "user", "content": [{"type": "text", "text": prompt}]}]
)
self.results[str(i)] = {
"prompt": prompt,
"video_url": response.choices[0].message.content,
"status": "success"
}
# 立即保存进度
self.save_progress()
except Exception as e:
self.results[str(i)] = {
"prompt": prompt,
"error": str(e),
"status": "failed"
}
self.save_progress()
return self.results
10. 性能监控和告警
import time
from dataclasses import dataclass
from typing import Optional
@dataclass
class PerformanceMetrics:
request_count: int = 0
success_count: int = 0
failed_count: int = 0
total_latency: float = 0.0
avg_latency: float = 0.0
class PerformanceMonitor:
def __init__(self):
self.metrics = PerformanceMetrics()
def record_request(self, success: bool, latency: float):
self.metrics.request_count += 1
self.metrics.total_latency += latency
if success:
self.metrics.success_count += 1
else:
self.metrics.failed_count += 1
self.metrics.avg_latency = self.metrics.total_latency / self.metrics.request_count
# 告警检查
if self.metrics.failed_count / self.metrics.request_count > 0.1:
self.send_alert("失败率超过 10%")
def send_alert(self, message):
print(f"⚠️ ALERT: {message}")
# 发送邮件/钉钉/Slack 通知
monitor = PerformanceMonitor()
def create_video_monitored(prompt):
start_time = time.time()
success = False
try:
response = openai.ChatCompletion.create(
model="sora2_video",
messages=[{"role": "user", "content": [{"type": "text", "text": prompt}]}]
)
success = True
return response
finally:
latency = time.time() - start_time
monitor.record_request(success, latency)
print(f"Metrics: {monitor.metrics}")
🎯 实践建议: 对于需要在生产环境稳定运行 Sora 2 API 的项目,我们建议参考 API易 apiyi.com 提供的企业级最佳实践文档。该文档包含完整的错误处理策略、成本优化方案和高可用架构设计,帮助企业客户快速构建可靠的视频生成服务。
📊 参数组合推荐方案
方案 1: 快速测试方案
适用场景: 开发调试、快速验证
response = openai.ChatCompletion.create(
model="sora2_video",
messages=[{"role": "user", "content": [{"type": "text", "text": prompt}]}],
quality="standard", # 标准质量,生成更快
aspect_ratio="16:9",
seed=42 # 固定种子,便于复现
)
方案 2: 生产发布方案
适用场景: 正式内容发布
response = openai.ChatCompletion.create(
model="sora2_video",
messages=[{"role": "user", "content": [{"type": "text", "text": prompt}]}],
quality="hd", # 高清质量
aspect_ratio="9:16", # 根据平台选择
request_timeout=600 # 10 分钟超时
)
方案 3: 批量生成方案
适用场景: 大规模视频生成
from concurrent.futures import ThreadPoolExecutor
def generate_batch(prompts):
with ThreadPoolExecutor(max_workers=5) as executor:
futures = [
executor.submit(
openai.ChatCompletion.create,
model="sora2_video",
messages=[{"role": "user", "content": [{"type": "text", "text": p}]}],
quality="hd"
)
for p in prompts
]
return [f.result() for f in futures]
🔍 常见问题 FAQ
Q1: 如何提高视频生成的成功率?
建议:
- ✅ 提示词长度控制在 50-200 字
- ✅ 使用具体、可视化的描述
- ✅ 设置合理的超时时间(300-600 秒)
- ✅ 实现自动重试机制(最多 3 次)
- ✅ 避免高峰期调用
Q2: API 调用速率限制是多少?
限制:
- 免费用户: 10 次/分钟
- 付费用户: 30 次/分钟
- 企业用户: 100 次/分钟(可申请提高)
建议: 对于高频调用场景,推荐通过 API易 apiyi.com 申请企业套餐,获得更高的速率限制和优先支持。
Q3: 如何优化 API 调用成本?
成本优化策略:
- ✅ 开发环境使用
quality="standard" - ✅ 使用缓存机制,避免重复生成相同内容
- ✅ 批量生成时使用并发控制,避免速率限制
- ✅ 设置每日预算上限,防止意外超支
- ✅ 充值时选择大额套餐享受折扣
Q4: 视频生成失败如何排查?
排查步骤:
- 检查 API Key 是否正确
- 检查余额是否充足
- 检查提示词是否包含违规内容
- 检查参数格式是否正确
- 查看错误响应中的
error.code字段 - 联系 API易 apiyi.com 技术支持获取帮助
Q5: 支持自定义视频时长吗?
当前状态: API易 Sora 2 API 目前仅支持 10 秒固定时长。
未来计划: API易团队正在测试更多时长选项,预计未来会开放 5 秒、10 秒、15 秒、20 秒等多种选择。建议关注 API易 apiyi.com 的功能更新公告。
📚 延伸阅读
推荐文章
- 《5 分钟上手 Sora 2 API》 – 快速入门教程
- 《Sora 2 提示词进阶指南》 – 提示词优化技巧
- 《Sora 2 图生视频完全攻略》 – 图生视频最佳实践
- 《用 Sora 2 API 打造自动化系统》 – 企业级应用架构
官方资源
- API 文档: https://docs.apiyi.com/sora-2-api
- 代码示例库: https://github.com/apiyi/sora-2-examples
- 技术支持: [email protected]
📖 深入学习: 本文涵盖了 API 参数的完整知识体系,但要真正掌握 Sora 2 API,还需要结合实际项目进行大量实践。我们建议通过 API易 apiyi.com 提供的免费试用额度进行充分测试,并参考平台上的实战案例库,快速积累经验。
🎯 总结
本文深度解析了 API易 Sora 2 API 的 15 个核心参数和 10 大生产环境最佳实践:
核心参数掌握:
- ✅ 3 个必需参数: model, messages, API Key
- ✅ 5 个内容控制参数: aspect_ratio, duration, style, quality, seed
- ✅ 3 个性能调优参数: timeout, retry_policy, priority
最佳实践应用:
- 环境变量管理
- 请求日志追踪
- 异步处理队列
- 成本监控控制
- 视频持久化
- 提示词模板化
- 批量生成优化
- A/B 测试框架
- 错误恢复机制
- 性能监控告警
下一步行动:
- 🔧 在开发环境实践参数组合
- 📊 搭建完整的监控和日志系统
- 🚀 构建生产级视频生成服务
- 💡 探索更多高级应用场景
记住: 参数只是工具,真正的价值在于将技术转化为业务成果。持续实践、优化、迭代,才能充分发挥 Sora 2 API 的潜力!
关于作者
本文由 APIYI 技术团队编写。API易致力于为开发者提供最先进的 AI 大模型 API 服务,包括 GPT、Claude、Gemini、Sora 等主流模型的统一接口。
如果你正在寻找稳定、高效、价格合理的 AI API 服务,欢迎访问 API易 apiyi.com 了解更多。我们提供:
- ✅ 完善的参数文档和 API 参考
- ✅ 丰富的代码示例和最佳实践
- ✅ 专业的技术支持和问题排查
- ✅ 企业级 SLA 保障和优先服务
关键词: Sora 2 API, API 参数, 性能优化, 最佳实践, 错误处理, API易, 视频生成 API
更新日期: 2025-10-02
版本: v1.0