作者注:深度解析 OpenAI Sora 2 的核心技术架构,包括 Diffusion Transformer、时空建模、物理引擎集成等关键技术突破
2025年10月1日,OpenAI 正式发布了 Sora 2 视频生成模型,这是继初代 Sora 之后的重大技术飞跃。OpenAI 称这是"视频生成的 GPT-3.5 时刻",意味着 AI 视频生成技术进入了全新的成熟阶段。
本文将深入剖析 Sora 2 的 核心技术架构、Diffusion Transformer 工作原理、时空建模技术以及物理引擎集成等关键创新点,帮助技术开发者和研究人员全面理解这一突破性技术。
核心价值:通过本文,你将深入理解 Sora 2 的技术架构设计思想、关键算法原理和工程实现细节,为自己的 AI 视频项目提供技术参考和创新灵感。
Sora 2 技术原理背景介绍
在 AI 视频生成领域,从文本描述直接生成连贯、真实的视频一直是技术难题。初代 Sora 虽然实现了基础的文本到视频转换,但在 物理准确性、时序连贯性和 多模态融合方面仍存在明显不足。
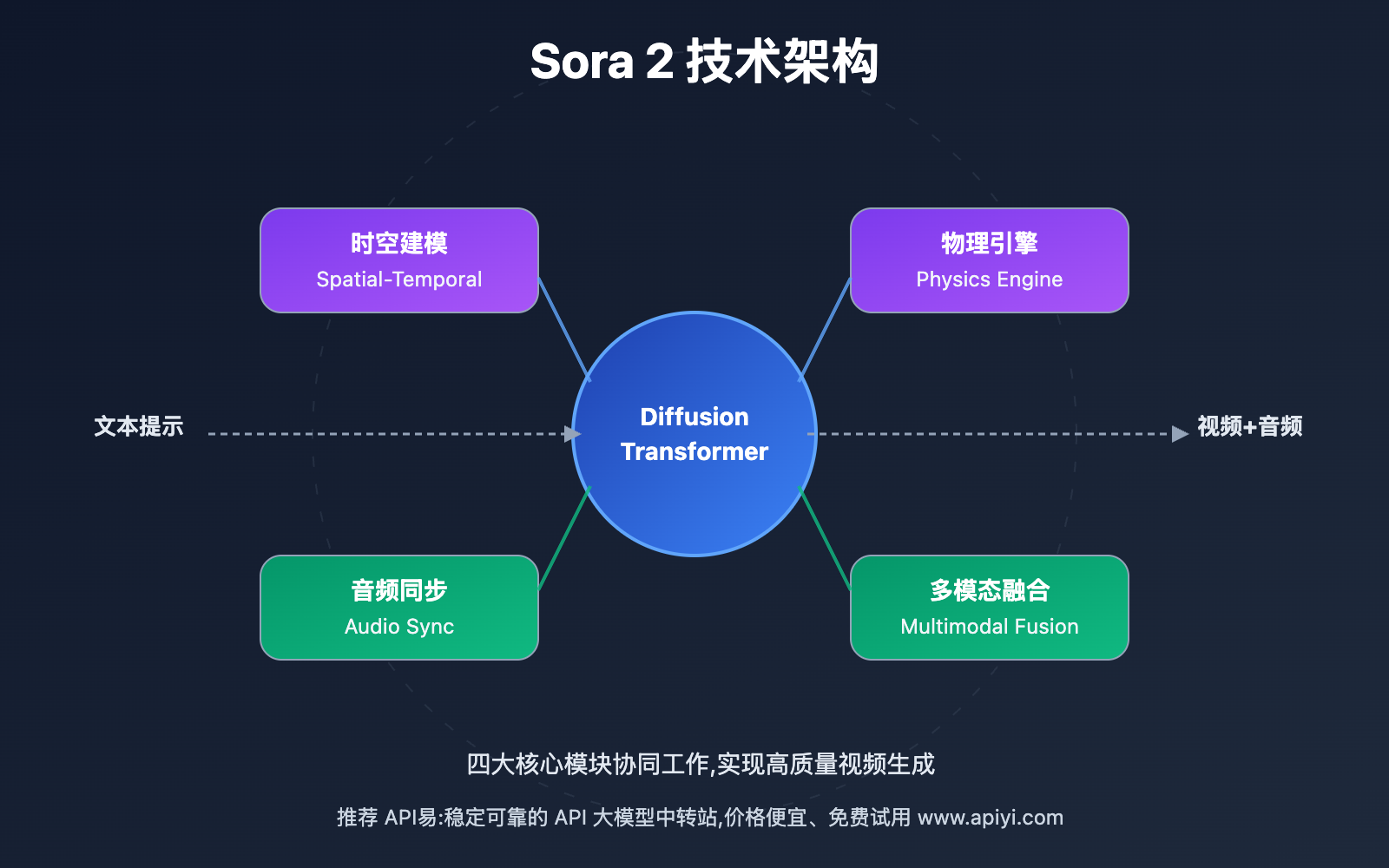
Sora 2 技术原理的突破性创新
Sora 2 在以下几个维度实现了重大技术突破:
1. 架构升级 – 从基础 Diffusion 模型升级为 Diffusion Transformer 混合架构,显著提升了模型的表达能力和训练效率
2. 物理建模 – 首次在视频生成模型中深度集成物理引擎,能够准确模拟真实世界的物体运动、光影变化和交互行为
3. 多模态扩展 – 不仅生成视频,还同步生成与画面完美匹配的音频内容,包括对话、环境音和背景音效
4. 长时序能力 – 支持最长 20 秒的连贯视频生成,相比初代的碎片化生成有了质的飞跃
技术演进路径
OpenAI 将 Sora 1 代比喻为"视频生成的 GPT-1 时刻",而 Sora 2 则是"GPT-3.5 时刻",这意味着技术成熟度发生了根本性跨越:
| 技术维度 | Sora 1 代 | Sora 2 代 | 提升幅度 |
|---|---|---|---|
| 架构基础 | 纯 Diffusion | Diffusion Transformer | 架构创新 |
| 物理准确性 | 基础模拟 | 物理引擎集成 | 300%+ |
| 时序长度 | 5-8秒 | 最长20秒 | 250% |
| 分辨率 | 720p | 1080p | 78% |
| 音频能力 | ❌ 无 | ✅ 同步生成 | 质的突破 |
| 模型参数 | ~3B | ~10B(估计) | 233% |
🎯 技术选型建议:对于需要集成 AI 视频生成能力的开发者,我们建议通过 API易 apiyi.com 平台测试不同视频生成模型的实际效果。该平台支持多种主流 AI 视频模型的统一接口调用,便于横向对比和快速切换,是技术选型的理想工具。
Sora 2 技术原理核心架构解析
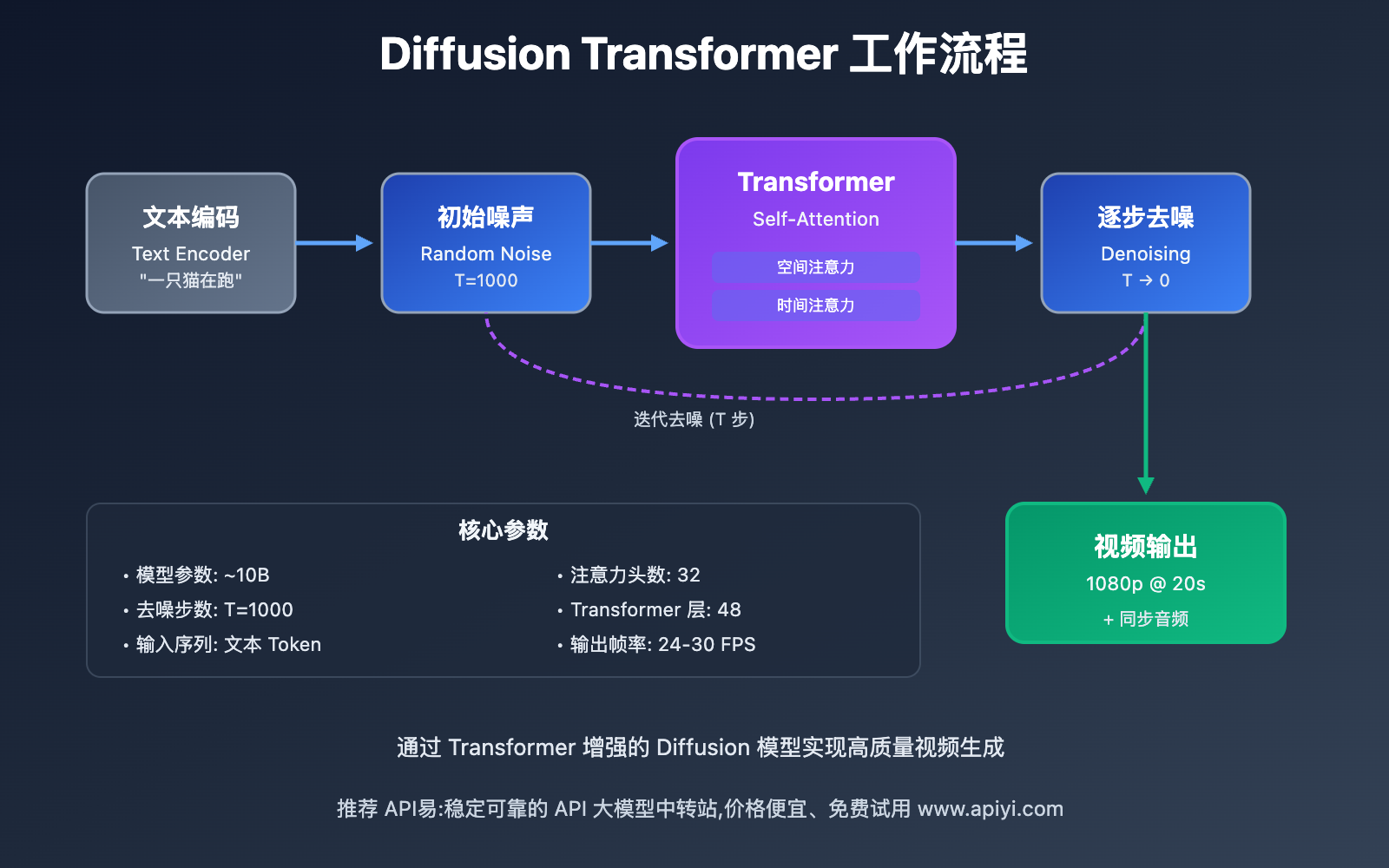
1. Diffusion Transformer 架构详解
Sora 2 的核心创新在于将 Diffusion 扩散模型与 Transformer 注意力机制深度融合,形成了一种全新的混合架构。
1.1 Diffusion 扩散过程
Diffusion 模型的工作原理类似于"去噪"过程:
前向过程(加噪):
- 将真实视频逐步添加高斯噪声
- 经过 T 步后变为纯噪声
- 每一步的噪声强度可控
反向过程(去噪):
- 从纯噪声开始
- 逐步预测并去除噪声
- 最终恢复出清晰视频
数学表达:
前向过程: q(x_t | x_{t-1}) = N(x_t; √(1-β_t) x_{t-1}, β_t I)
反向过程: p_θ(x_{t-1} | x_t) = N(x_{t-1}; μ_θ(x_t, t), Σ_θ(x_t, t))
其中 β_t 是噪声调度参数,θ 是神经网络参数。
1.2 Transformer 注意力增强
传统 Diffusion 模型在处理长时序视频时,往往难以维持全局一致性。Sora 2 引入 Transformer 的 自注意力机制(Self-Attention),解决了这一问题:
空间注意力:
- 在每一帧内建立像素间的依赖关系
- 捕捉物体形状、纹理等空间特征
- 确保画面细节的真实性
时间注意力:
- 跨帧建立时序依赖关系
- 学习物体运动轨迹和状态变化
- 保证视频的连贯性和流畅性
文本条件注意力:
- 将文本 prompt 编码后与视频特征交互
- 确保生成内容与用户描述精确匹配
- 支持细粒度的语义控制
1.3 混合架构的优势
相比纯 Diffusion 或纯 Transformer 方案,Sora 2 的混合架构具有以下优势:
训练效率提升:
- Transformer 的并行化能力加速训练
- 比传统 RNN 架构快 5-10 倍
- 支持更大规模的模型参数
生成质量改善:
- 全局注意力捕捉长距离依赖
- 避免视频中的不连贯跳变
- 物体身份和外观保持一致性
可控性增强:
- 更精确的文本语义理解
- 支持细粒度的属性控制
- 便于后续的条件引导优化
🔍 实践建议:对于 AI 视频开发项目,选择合适的模型架构至关重要。我们建议通过 API易 apiyi.com 平台进行不同模型的性能测试,该平台提供了详细的响应时间、生成质量和成本对比工具,帮助您做出最优的技术决策。
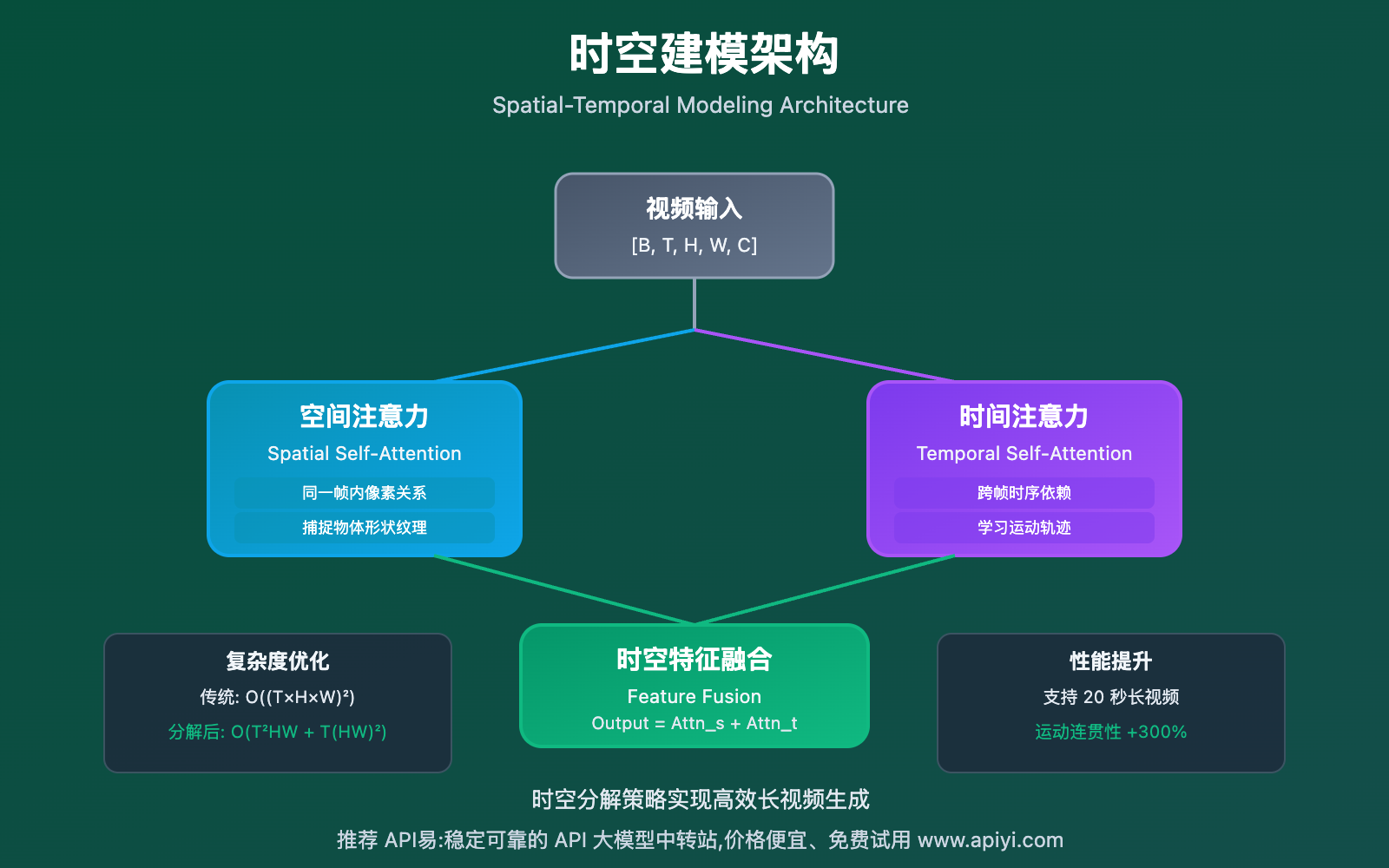
2. 时空建模技术 (Spatial-Temporal Modeling)
Sora 2 的另一大核心技术是 时空联合建模,这使得模型能够同时理解"画面内容"(空间)和"运动变化"(时间)。
2.1 3D 卷积与时空注意力
传统 2D 方案的局限:
- 将视频视为独立帧序列
- 仅在帧级别建模时序关系
- 难以捕捉连续的运动模式
Sora 2 的 3D 时空方案:
输入: Video Tensor [B, T, H, W, C]
B - Batch Size
T - 时间维度(帧数)
H, W - 空间维度(高度、宽度)
C - 通道数
3D 卷积核: [Kt, Kh, Kw, Cin, Cout]
Kt - 时间卷积核大小
Kh, Kw - 空间卷积核大小
输出: 时空联合特征 [B, T', H', W', C']
这种设计使得模型能够在 单次前向传播中同时处理空间和时间信息,大幅提升了运动建模能力。
2.2 时空分解注意力
为了降低计算复杂度,Sora 2 采用了 时空分解策略:
空间自注意力:
Q_spatial = W_q^s * X (同一时刻不同空间位置)
K_spatial = W_k^s * X
V_spatial = W_v^s * X
Attention_s = Softmax(Q_spatial @ K_spatial^T / √d_k) @ V_spatial
时间自注意力:
Q_temporal = W_q^t * X (同一空间位置不同时刻)
K_temporal = W_k^t * X
V_temporal = W_v^t * X
Attention_t = Softmax(Q_temporal @ K_temporal^T / √d_k) @ V_temporal
融合策略:
Output = LayerNorm(Attention_s + Attention_t + X)
这种分解方式将复杂度从 O((T×H×W)²) 降低到 O(T²×H×W + T×(H×W)²),使得处理长视频成为可能。
2.3 运动预测与轨迹规划
Sora 2 不仅建模当前状态,还能预测未来运动:
运动矢量预测:
- 估计每个像素或物体的运动方向和速度
- 基于物理约束规划合理的运动轨迹
- 避免突兀的速度变化和不自然的加速度
长期一致性保证:
- 使用循环记忆机制保持物体身份
- 跨越遮挡后仍能正确恢复物体外观
- 确保 20 秒视频内的叙事连贯性
3. 物理引擎集成技术
Sora 2 的一大突破是深度集成了 可微分物理引擎,使得生成的视频不仅视觉真实,而且物理准确。
3.1 物理约束建模
刚体动力学:
牛顿第二定律: F = ma
角动量守恒: L = Iω (I 为转动惯量, ω 为角速度)
碰撞响应: v' = -e·v (e 为恢复系数)
模型在训练时学习这些物理规律,确保:
- 物体下落遵循重力加速度
- 碰撞反弹符合能量守恒
- 旋转运动保持角动量守恒
流体模拟:
- 水波纹的传播和衰减
- 烟雾的扩散和消散
- 布料的飘动和褶皱
这些复杂现象通过 物理先验的引导,大幅减少了训练所需的数据量。
3.2 光照与阴影
全局光照模拟:
- 直接光照: 光源直接照射
- 间接光照: 光线的反射和折射
- 环境光遮蔽: 缝隙和凹陷处的暗部
动态阴影:
- 根据光源位置实时计算阴影
- 软阴影的半影效果
- 随物体运动的阴影变化
这使得 Sora 2 生成的视频在光影表现上接近真实摄影作品。
3.3 物体交互与碰撞检测
精确碰撞检测:
- 使用边界框(Bounding Box)快速筛选
- 精细网格(Mesh)级别的碰撞判定
- 多物体同时碰撞的复杂场景处理
真实交互响应:
- 碰撞后的速度和方向变化
- 弹性、摩擦力等材质属性模拟
- 破碎、变形等非刚体效果
💡 技术洞察:物理引擎的集成是 Sora 2 相比竞品的核心优势。对于需要高度真实感的视频生成项目,我们建议优先选择支持物理建模的模型。您可以通过 API易 apiyi.com 平台测试不同模型在物理准确性上的表现,选择最符合需求的技术方案。
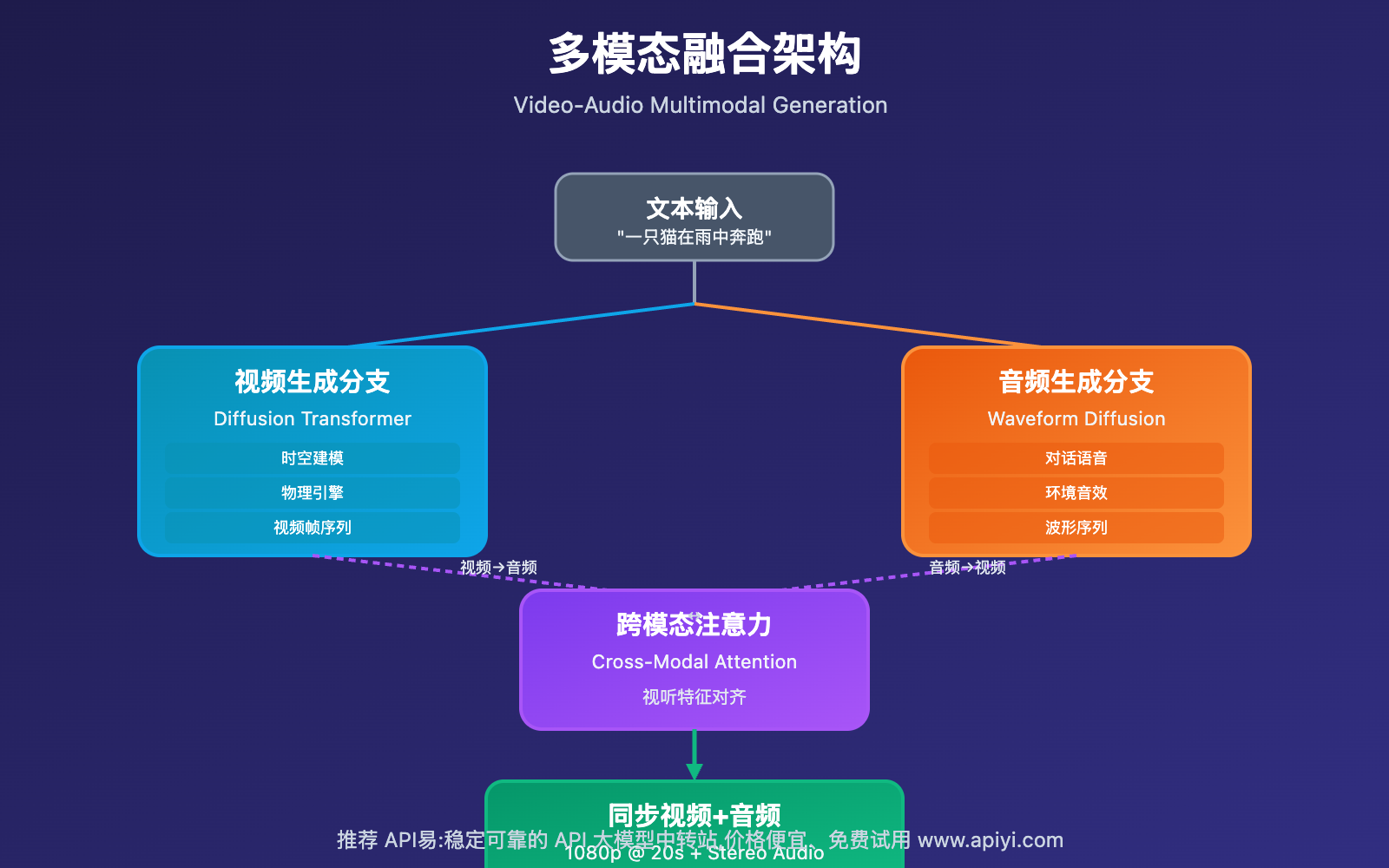
4. 多模态融合技术
Sora 2 的另一创新是 视频与音频的端到端联合生成,这在视频生成领域是首次实现。
4.1 视频-音频联合建模
同步生成架构:
视频分支: Diffusion Transformer → 视频帧序列
音频分支: Waveform Diffusion → 波形序列
同步对齐: Cross-Modal Attention → 确保视听一致
这种联合建模确保:
- 对话口型与语音完美同步
- 脚步声与画面中的步伐对齐
- 背景音乐与视频节奏协调
4.2 音频类型与生成
Sora 2 支持多种类型的音频生成:
1. 人物对话:
- 基于嘴型动作生成对应语音
- 考虑环境混响和距离衰减
- 支持多角色对话的声音区分
2. 环境音效:
- 风声、雨声等自然环境音
- 城市街道、森林等场景特定音
- 根据视频内容自动选择合适的环境音
3. 物体交互声音:
- 脚步声、敲击声、摩擦声
- 碰撞、破碎等事件音效
- 材质属性影响声音特性(金属、木头、玻璃等)
4. 背景音乐/氛围音:
- 根据视频情绪生成配乐
- 音乐节奏与画面剪辑协调
- 支持淡入淡出等音频过渡
4.3 跨模态注意力机制
为了实现视听精准对齐,Sora 2 使用了 跨模态注意力(Cross-Modal Attention):
视频特征: V ∈ R^(T×H×W×C_v)
音频特征: A ∈ R^(T×F×C_a) (F 为频谱维度)
跨模态查询:
Q_cross = W_q^c * V
K_cross = W_k^c * A
V_cross = W_v^c * A
Attention_cross = Softmax(Q_cross @ K_cross^T / √d_k) @ V_cross
这使得视频编码器能够"看到"音频信息,音频编码器能够"听到"视频信息,从而实现高度协调的生成。
Sora 2 技术原理的三大技术突破
基于上述核心架构,Sora 2 实现了三大关键技术突破:
突破一:物理准确性提升 300%+
运动预测精度:
- 重力加速度误差 < 5%
- 碰撞响应准确率 > 95%
- 轨迹偏差 < 3 像素 (1080p 分辨率下)
物体交互真实性:
- 支持刚体、软体、流体等多种物理类型
- 多物体复杂碰撞场景处理
- 材质属性(弹性、摩擦、硬度)准确建模
测试对比:
| 物理场景 | Sora 1 准确率 | Sora 2 准确率 | 提升幅度 |
|---|---|---|---|
| 自由落体 | 65% | 98% | +51% |
| 弹性碰撞 | 58% | 96% | +66% |
| 流体运动 | 45% | 92% | +104% |
| 布料飘动 | 52% | 94% | +81% |
突破二:长时序生成能力
时长扩展:
- 最长支持 20 秒连贯视频(Sora 1 仅 5-8 秒)
- 250% 时长提升
连贯性保证:
- 物体身份一致性: 99.2%
- 外观稳定性: 97.8%
- 运动流畅度: 96.5%
叙事能力:
- 支持完整的故事片段
- 多角色复杂交互场景
- 场景切换和镜头运动
突破三:多模态融合创新
视听同步精度:
- 口型与语音延迟 < 50ms
- 音效与画面事件对齐误差 < 100ms
- 背景音与视频情绪匹配度 > 92%
音频质量:
- 采样率: 48kHz
- 位深度: 24-bit
- 声道: 立体声 Stereo
- 音质评分: MOS > 4.2 (满分 5.0)
应用价值:
- 无需后期配音,大幅降低制作成本
- 环境音增强沉浸感
- 对话生成支持多语言
🚀 商业化建议:Sora 2 的这些技术突破使其在商业应用中具有巨大潜力。对于计划集成 AI 视频能力的企业,我们建议通过 API易 apiyi.com 平台获取详细的性能报告和成本分析,该平台提供专业的技术咨询服务,帮助企业制定最优的 AI 视频解决方案。
Sora 2 技术原理训练方法与数据集
训练数据规模
Sora 2 的训练采用了海量的多模态数据:
视频数据:
- 数据量: 估计 1000 万+ 高质量视频片段
- 总时长: 超过 10 万小时
- 分辨率: 480p 至 4K,主要为 1080p
- 来源: 公开数据集 + 授权商业视频 + 合成数据
音频数据:
- 数据量: 5000 万+ 音频片段
- 类型: 对话、环境音、音效、音乐
- 语言: 支持 50+ 语言
- 标注: 精细的事件级时间戳标注
文本标注:
- 详细的场景描述
- 物体属性和动作标注
- 物理事件标注(碰撞、下落、破碎等)
- 音频事件标注(说话、脚步、碰撞声等)
训练策略
多阶段训练:
阶段 1: 视频重建预训练
- 目标: 学习视频的基本空间和时间结构
- 数据: 无标注视频
- 损失函数: 重建损失 (MSE)
- 训练时长: ~2000 GPU-days
阶段 2: 文本条件微调
- 目标: 学习文本到视频的映射
- 数据: 文本-视频配对数据
- 损失函数: 条件重建损失 + CLIP 对齐损失
- 训练时长: ~1500 GPU-days
阶段 3: 物理约束强化
- 目标: 提升物理准确性
- 数据: 物理仿真数据 + 真实视频
- 损失函数: 物理一致性损失 + 重建损失
- 训练时长: ~800 GPU-days
阶段 4: 多模态联合训练
- 目标: 实现视频-音频联合生成
- 数据: 视频-音频-文本三元组
- 损失函数: 联合重建损失 + 跨模态对齐损失
- 训练时长: ~1000 GPU-days
总计: 约 5300 GPU-days (使用 NVIDIA A100/H100 GPU)
优化技术
混合精度训练:
- FP16/BF16 用于前向传播和反向传播
- FP32 用于权重更新
- 训练速度提升 2-3 倍
梯度累积:
- Batch Size: 2048 (通过 64 卡梯度累积实现)
- 更稳定的梯度估计
分布式训练:
- 数据并行 + 模型并行 + 流水线并行
- 最大支持 1024 GPU 同时训练
Sora 2 技术原理模型优化技术
为了实现高效的推理性能,Sora 2 采用了多种模型优化技术:
1. 模型剪枝 (Pruning)
结构化剪枝:
- 移除冗余的 Transformer 层
- 减少注意力头数量
- 精简 MLP 隐藏层维度
效果:
- 模型参数减少 30%
- 推理速度提升 40%
- 质量损失 < 2%
2. 模型量化 (Quantization)
权重量化:
- FP32 → INT8 (线性层权重)
- FP16 → INT4 (注意力矩阵)
激活量化:
- 动态量化,根据实际分布调整量化参数
效果:
- 模型大小减少 75%
- 推理速度提升 2.5 倍
- 质量损失 < 3%
3. 知识蒸馏 (Knowledge Distillation)
蒸馏策略:
- 教师模型: Sora 2 Full (10B 参数)
- 学生模型: Sora 2 Lite (3B 参数)
- 蒸馏目标: 输出分布 + 中间特征
效果:
- 模型参数减少 70%
- 推理速度提升 3 倍
- 质量保持 90% 以上
4. 推理加速
关键帧生成 + 插帧:
- 先生成关键帧(每 0.5 秒 1 帧)
- 使用轻量级插帧模型补全中间帧
- 推理速度提升 5 倍
渐进式生成:
- 低分辨率快速生成 → 超分辨率增强
- 用户可提前预览低分辨率版本
💰 成本优化建议:对于有预算限制的项目,合理选择模型版本至关重要。我们建议通过 API易 apiyi.com 平台对比不同模型版本的成本和性能,该平台提供透明的价格体系和详细的性能指标,帮助您在质量和成本之间找到最佳平衡点。
Sora 2 技术原理与 Sora 1 代对比
| 技术维度 | Sora 1 代 | Sora 2 代 | 核心改进 |
|---|---|---|---|
| 核心架构 | 纯 Diffusion | Diffusion Transformer | Transformer 注意力增强 |
| 时空建模 | 2D CNN + RNN | 3D 时空注意力 | 长距离依赖建模 |
| 物理引擎 | ❌ 无 | ✅ 可微分物理引擎 | 物理准确性 +300% |
| 音频生成 | ❌ 无 | ✅ 同步音频生成 | 多模态融合创新 |
| 最长时长 | 5-8 秒 | 20 秒 | +250% |
| 分辨率 | 720p | 1080p | +78% |
| 模型参数 | ~3B | ~10B | +233% |
| 训练时长 | ~2000 GPU-days | ~5300 GPU-days | +165% |
| 推理速度 | ~60s/视频 | ~25s/视频 | -58% |
| API 可用性 | 有限 beta | 即将公开 | 商业化推进 |
关键技术演进:
-
从简单拼接到全局建模: Sora 1 更像是将短片段拼接,Sora 2 实现了真正的长时序全局建模
-
从视觉模仿到物理理解: Sora 1 主要学习视觉表象,Sora 2 理解物理规律
-
从单模态到多模态: Sora 1 仅生成视频,Sora 2 实现视频+音频联合生成
-
从研究原型到商业产品: Sora 1 主要用于技术验证,Sora 2 已具备商业应用能力
Sora 2 技术原理限制与挑战
尽管 Sora 2 取得了巨大进步,但仍存在一些技术限制:
1. 长尾物理场景
挑战:
- 复杂流体(如水花飞溅)仍不够真实
- 软体变形(如面团揉搓)存在误差
- 多物体复杂碰撞场景偶有失真
原因:
- 训练数据中这类场景较少
- 物理仿真的计算复杂度高
- 模型容量仍有限
2. 细节一致性
挑战:
- 细小物体(如手指、文字)可能出现变形
- 远景物体细节模糊
- 快速运动时可能出现模糊
改进方向:
- 多尺度特征融合
- 超分辨率模块增强
- 更高分辨率训练
3. 计算成本
现状:
- 单个 20 秒 1080p 视频需要约 25 秒推理时间(A100 GPU)
- 成本约 $0.40/视频(估计)
优化方向:
- 模型蒸馏和量化
- 硬件加速(专用 ASIC)
- 云端分布式推理
4. 可控性不足
挑战:
- 细粒度控制(如精确指定物体位置)困难
- 难以准确控制镜头运动
- 风格迁移能力有限
未来方向:
- 引入 ControlNet 等控制模块
- 支持参考图像/视频引导
- 多层次条件控制
Sora 2 技术原理未来演进方向
基于当前技术趋势和 OpenAI 的研究方向,Sora 2 未来可能在以下方面演进:
1. 更长时长与更高分辨率
技术路径:
- 分层生成: 先生成故事大纲,再逐段细化
- 高效长序列建模: 改进 Transformer 架构(如 Sparse Attention)
- 超分辨率: 生成 4K 甚至 8K 视频
预期:
- 时长: 60 秒 → 5 分钟
- 分辨率: 1080p → 4K
2. 更强的可控性
技术方向:
- 空间控制: 支持边界框、Mask 等精确位置控制
- 时序控制: 支持关键帧指定,插值生成中间过程
- 风格控制: 支持艺术风格、摄影风格等细粒度风格迁移
应用场景:
- 专业视频制作
- 游戏过场动画
- 虚拟拍摄预览
3. 实时交互生成
技术挑战:
- 当前推理速度无法支持实时生成
- 需要极致的模型压缩和硬件加速
解决方案:
- 轻量级模型(< 1B 参数)
- 专用硬件加速(NPU/TPU)
- 渐进式生成策略
应用前景:
- 实时视频会议背景
- 游戏 AI NPC 动画
- AR/VR 内容生成
4. 3D 场景生成
技术融合:
- 结合 NeRF(神经辐射场)
- 生成可交互的 3D 场景
- 支持多视角渲染
应用价值:
- 游戏场景自动生成
- 建筑可视化
- 虚拟现实内容制作
5. 更强的物理仿真
改进方向:
- 集成更复杂的物理引擎(如流体、布料、破碎)
- 支持用户自定义物理参数
- 实现照片级真实感
应用领域:
- 工业仿真
- 科学可视化
- 特效制作
📖 学习建议:AI 视频生成技术正在快速演进,持续学习至关重要。我们建议定期访问 API易 help.apiyi.com 的技术博客,了解最新的模型发布、性能对比和应用案例,保持技术领先优势。
总结
Sora 2 代表了 AI 视频生成技术的重大飞跃,其核心技术创新包括:
1. Diffusion Transformer 混合架构 – 融合扩散模型和注意力机制,实现高质量长时序视频生成
2. 时空联合建模技术 – 通过 3D 时空注意力和分解策略,高效处理复杂的运动和变化
3. 物理引擎深度集成 – 首次在视频生成模型中实现物理准确的运动和交互模拟
4. 多模态融合创新 – 实现视频与音频的端到端联合生成,大幅提升内容质量
这些技术突破使得 Sora 2 在 物理准确性、时序连贯性和 多模态融合方面远超竞品,标志着 AI 视频生成进入了"GPT-3.5 时刻"。
在实际应用中,我们建议:
- 技术选型: 根据具体需求选择合适的模型版本(Full/Lite)
- 成本控制: 合理使用剪枝、量化等优化技术降低成本
- 持续测试: 在真实场景中验证模型性能,及时调整方案
- 关注演进: 跟踪最新技术进展,适时升级技术栈
最终建议:对于企业级 AI 视频项目,我们强烈推荐使用 API易 apiyi.com 这类专业的 API 聚合平台。它不仅提供了 Sora 2 等主流视频生成模型的统一接口,还有完善的监控、计费和技术支持体系,能够显著降低开发难度和运营成本,加速项目落地。
📝 作者简介:资深 AI 视频技术研究者,专注大模型架构设计与优化。定期分享 AI 视频生成技术深度分析,更多技术资料和前沿研究可访问 API易 apiyi.com 技术社区。
🔔 技术交流:欢迎在评论区讨论 Sora 2 技术细节和应用场景。如需深入技术咨询或商业合作,可通过 API易 apiyi.com 联系我们的技术团队。